1ヶ月ほど読み進めていた「データ指向アプリケーションデザイン」を読了しました。
オライリーから出版されている本の中でも、かなり分厚い部類の書籍だったのと、章ごとの情報量が凄かったので結構、時間がかかってしまいました。

個人的には難易度の高い書籍だと思うのですが、それでも多くの方からオススメされてきた書籍でもあります。
今まで読んでは飽き...読んでは飽き...を繰り返していましたが、ようやく一貫して読了したので簡単に書評を書いてみたいと思います。

デカい...! 分厚い...!
データ指向アプリケーションとは何か
元々、コンピューターは演算処理を高速化するために開発されました。
当時は簡単な演算処理をするのにも多くの時間とリソースが必要だったことでしょう。僕は実物を見たことはないのですが、古いコンピューターでの演算といえば「パンチカード」が有名です。
しかし、今日ではCPU処理性能が向上したこともあり、自分のような一般人にとっては演算処理がボトルネックになることは、ほとんどなく快適にコンピュータを使用することができます。
とはいえ気候予測や物理計算などの分野では、演算処理に特化したスーパーコンピューターが活用されています。

引用元: パンチカードでプログラミングする方法 / How to program on the punch card
そして時代は変わり、インターネットの普及によって多くのアプリケーションが全世界で公開されており、大量のデータが毎日のように作成されています。
今となってはアプリケーションのボトルネックは、データ(量、複雑さ、変化)です。
どのようにデータを扱いアプリケーションを稼働させるかという点に重点がおかれます。
まさしくこれが「データ指向」です。
本書ではデータ指向アプリケーションが、取り組まねばならない3つの課題を中心に章が構成されています。
- 信頼性
- スケーラビリティ
- メンテナンス性
3つの課題に取り組むにあたって自然と、分散データや分散処理に触れられていきます。
詳しい内容については情報量が多すぎるので紹介できませんが、次に各章がどのように展開されていくのか紹介します。
章の展開について
この書籍は大きく3つの部から構成されています。
- 第Ⅰ部 データシステムの基礎
- 第Ⅱ部 分散データ
- 第Ⅲ部 導出データ
読んでいて面白いな...と感じたのが1章で「データ指向アプリケーション」についての説明が終わった後に、次の章からデータベース、ストレージの仕組み...が説明されていく点です。
自分の読書前のイメージだと、大規模データを扱うにあたってのグッド・バッドプラクティス、どういった特性に注意すべきかについての内容が、メインコンテンツだと思っていましたが違いました。
- データベースって何なのか
- RDBが人気なのは何故なのか
- NoSQLが誕生したのは何故なのか
- RDB・NoSQLの使い所について
- そもそもデータはどうやって記録されているのか
- 読み取ったデータはどうやって展開されるのか
etc...
ここまで第Ⅰ部の説明が終わってから、ようやく第Ⅱ部 分散データ(レプリケーション・パーティショニング)の内容が登場します。 というのも分散データを考えるにあたって、どのようにデータが記録されているのかを理解しておくことが重要だからだと思われます。 そして最後に、分散データをどのように処理するかという第Ⅲ部 導出データ(MapReduce・ストリーム処理)が登場します。
章の構成がとても良く出来ていると感じました。
読了して見える世界
以前、分散コンピューティング技法という書籍を読んだ際にも触れられてた内容なのですが、逐次処理が並行処理になった途端に複雑さが跳ね上がります。 第Ⅱ部でレプリケーションやパーティショニングといった内容が登場するわけですが、単にデータを複製・分割すれば万事解決というわけではなく様々な問題が発生するようになります。
例えば、レプリケーションの場合、マスターDBからレプリカA,B,Cへのデータ同期を行う必要があるとします。
まずデータ同期の方法を同期・非同期で行うかを決める必要があります。同期的に行うとデータ同期に時間はかかりますが、信頼性が高くエラーハンドリングが行いやすいでしょう。一方で非同期の場合、データ同期に時間はかからないですが、本当にデータが同期されたのか分からず信頼性が低くなります。
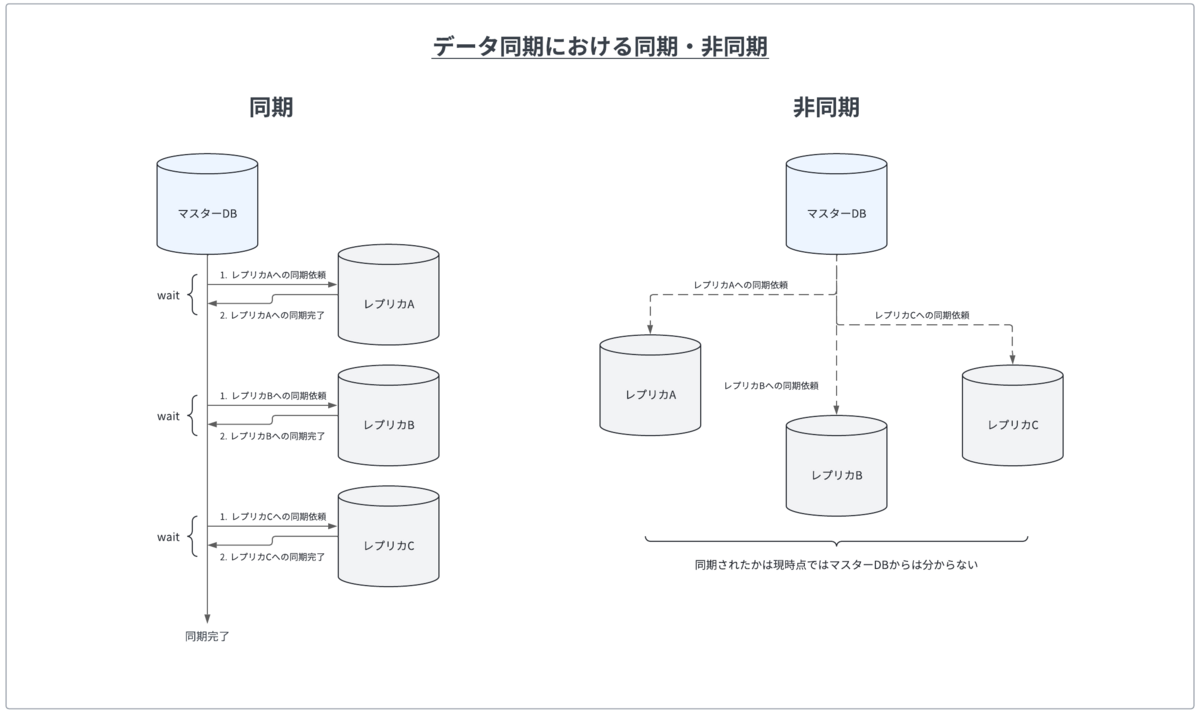
どちらも対処方法は考えられるものの、さらに別の問題が発生する可能性があります。
- 同期的にデータを同期する途中で、ネットワーク障害が発生した場合にどうするのか
- レプリカA,Bへの同期は成功したもののレプリカCへのデータ同期に失敗した場合に、ロールバックするのか
- マスターDBが何かしらの理由でダウンした場合にどうするのか
- レプリカA,B,Cから新たなマスターを決定する場合、どのように決定するのか
- マスターを決定した際に複数マスターが決定されてしまわないか
こういった問題に向き合い「信頼性・スケーラビリティ・メンテナンス性」をいかにして確保していくのかを検討するのが、データ指向アプリケーションデザインなのかなと思います。
自分はkubernetesやCloud Runなどを使ってサーバー分離やスケーリングを経験したことはありますが、複数台のレプリケーションやパーティショニングを行ったことはありません。安易にデータを分散すれば良いものだと考えていましたが、新たに発生するこれらの問題のことを考えると頭が痛いです...。
上記で挙げたよくある問題はミドルウェアがカバーしてくれているものもあります。
とはいえ、そもそもこういった問題を認知できていないと、技術選定やアルゴリズムを採用する際にトレードオフの判断をすることができません。
読了した今、単一のサーバー・DBから複数台のサーバー・DBになった時に起き得ることを、少しでも想定できるようになったのかなと感じています。
勝手に対象読者
書籍を翻訳された斎藤太郎さんが、膨大な情報を簡潔にまとめたスライドを公開されていました。
少しでも興味がある方は全体像が分かると思うので、ぜひ見てみてください。
おすすめできる人
- データとの向き合い方に興味がある
- 大量のデータをどのように分散・処理するのか興味がある
- 大規模なアプリケーションをどのように設計すれば良いのか興味がある
- データについて網羅的に学びたい
- これからデータ分散に取り組む
おすすめできない人
- データベースやストレージについて詳細に学びたい
- レプリケーション・パーティショニングについて具体的なやり方を知りたい
- アプリケーションの運用に携わったことがない
- サクッとデータ分散について学びたい
最後に
シンプルに情報のボリュームとページ量が多いので、ゆっくり読むことをおすすめしたいです。
自分の脳みそだと1日、1章読むのが限界でした。本当に1つ1つの章でアルゴリズムの解説や参考論文の紹介までされていて、情報のボリュームと質が素晴らしいです。
正直、読み切ることに必死だったので頭に入っている内容は半分以下だと思います。
ただ先ほど「章の展開」で触れたように、読了したことで全体像が見えたので再度、読み直した際にスムーズに頭に入ってくるのではないかと期待しています。1年後ぐらいにもう一度、読んでみます。
少しでも「ええな〜」と思ったらはてなスター・はてなブックマーク・シェアを頂けると励みになります。