こちらは僕が主催している清流elixir - connpassで扱った内容の備忘録になります。
現在は1ヶ月に一度を目処にオンラインで活動をしています。
今回は愛用してやまないElixirのパワフルなEnumモジュールについて、果たしてどのように作られているのか、すなわちどのようなコードが書かれているのかを掘り下げていきました。
動機としては良いプログラマーになるためには良いコードをたくさん読むのが手っ取り早いからです。とはいえ、いきなり言語のコードを読むのは大丈夫かなと思ったのですが、皆様のご助力もあり、何とかなりました。
参加者の皆さん、ありがとうございました🙇♂️
Enumモジュールについて🧪
Elixirでは関数群をモジュールという単位で管理することができます。オブジェクト指向言語で言うところのクラスに近いものでしょうが、継承の概念はありません。ただ関数をまとめるだけになります。
defmodule Sample do def foo(:a), do: 1 def foo(:b), do: 2 def foo(:c), do: 3 end
合わせてElixirには標準に実装されているモジュールがいくつかあります。その中でもパワフルなのは何と言ってもEnumモジュールです。Enumモジュールに定義されている関数は以下の3つのデータを第一引数に受け取り、処理を実行します。
- Lists ([1, 2, 3])
- Maps (%{foo: 1, bar: 2})
- Ranges (1..3)
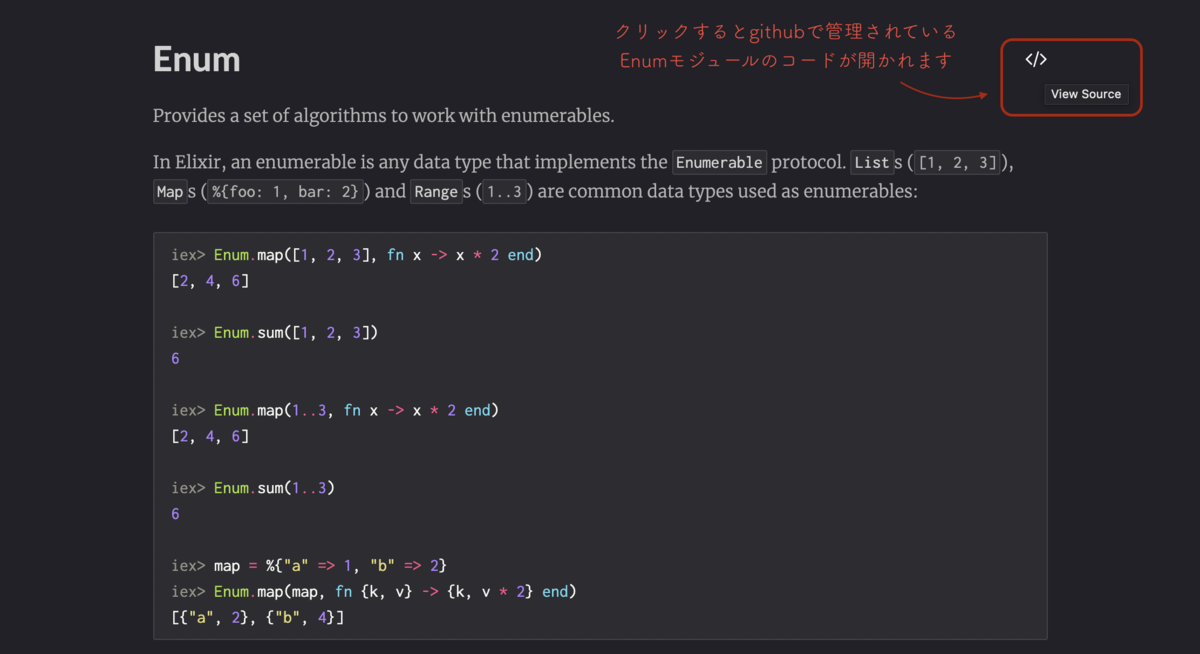
In Elixir, an enumerable is any data type that implements the Enumerable protocol.
Lists ([1, 2, 3]), Maps (%{foo: 1, bar: 2}) and Ranges (1..3) are common data types used as enumerables:
関数1つ1つを実行するだけではその真の力を発揮することは出来ません。このEnumモジュールの関数とパイプライン演算子(|>)を組み合わせることで、Enumモジュールは本当の力を発揮します。
1..100 |> Enum.to_list() |> Enum.filter(fn n -> n < 50 end) |> Enum.map(fn n -> n + 1 end) |> Enum.sum() |> IO.puts() # 1274
このように実行結果の戻り値がEnumモジュールに受け渡し可能な上記3つのデータ構造であれば、無限にパイプラインをつなげることが可能です。
頻繁に使用する関数🍺
勉強会の当日に参加者の皆さんに「Enumでよく使う関数って何ですか?」と尋ねたところ、map, filter, reduceがやはり人気でした。Enumの三種の神器ともいえる関数です。(他にもgroup_byやatなど...)
mapは各要素に対して関数を適応させる関数です。map関数が使用率が最も高いと判断したので、Enumモジュールに定義されているmap関数のコードを見てみることにします。
enum.exを掘り下げていく⛏
Enumモジュールが定義されているのはこちらのファイルです。
まずはmap関数を探してみます。コード内でdef mapと検索をかけてやれば簡単に見つけることが出来ました。
@spec map(t, (element -> any)) :: list def map(enumerable, fun) def map(enumerable, fun) when is_list(enumerable) do :lists.map(fun, enumerable) end def map(enumerable, fun) do reduce(enumerable, [], R.map(fun)) |> :lists.reverse() end
これがmap関数の実装です。1, 2行目はdialyxirという型アノテーションライブラリのための定義なので、今回は扱いません。その下にある2つの関数に注目していきます。
パターンマッチを使って2つのケースが想定されています。1つ目は第1引数のenumerableがリストの時です。その場合は単純にErlangのlistsモジュールに定義されているmap関数を呼び出しています。
:lists.map(fun, enumerable)
それ以外のケース、すなわち、List, Mapの場合にはファイル内に定義されているreduce/3関数が呼び出されています。
reduce(enumerable, [], R.map(fun)) |> :lists.reverse()
先程と同じようにdef reduceを検索してみると、以下のコードが見つかりました。なお、reduce関数は引数が2つのものと、3つのものがあり先程呼び出されていたのは引数が3つのものだったので、引数が2つのreduce関数については今回は取り扱いません。
def reduce(enumerable, acc, fun) when is_list(enumerable) do :lists.foldl(fun, acc, enumerable) end def reduce(first..last//step, acc, fun) do reduce_range(first, last, step, acc, fun) end def reduce(%_{} = enumerable, acc, fun) do reduce_enumerable(enumerable, acc, fun) end def reduce(%{} = enumerable, acc, fun) do :maps.fold(fn k, v, acc -> fun.({k, v}, acc) end, acc, enumerable) end def reduce(enumerable, acc, fun) do reduce_enumerable(enumerable, acc, fun) end
mapとは異なり、かなり多くのケースが想定されています。上から順にList, Range, Structs(構造体), Map, それ以外とマッチさせています。余談ですが、Elixir 1.12verからRangeのステップが指定出来るようになったそうです。
1..10//2 |> Enum.to_list() |> IO.inspect() # [1, 3, 5, 7, 9]
また、%_{}とすることでStructs(構造体)をマッチさせることが出来ます。こちらも初めて知りました。
defmodule Sample do def url(%_{}), do: IO.puts("match!") end %URI{ authority: "okb" } |> Sample.url() # match!
重要なのはreduce_enumerableという関数です。同じようにこのファイルに定義されています。
defp reduce_enumerable(enumerable, acc, fun) do Enumerable.reduce(enumerable, {:cont, acc}, fn x, acc -> {:cont, fun.(x, acc)} end) |> elem(1) end
何やら見慣れないモジュールを呼び出しています。Enumerableというのは何でしょうか。ヒントはEnumモジュールのドキュメントにあります。このような一文が書かれていました。
In Elixir, an enumerable is any data type that implements the Enumerable protocol
なのでEnumerableというのはモジュールではなく、protocol(プロトコル)であり、Enumerableプロトコルに定義されているreduce関数を呼び出しているということになります。
プロトコルについて🤔
プロトコルは他言語でいうところのインターフェースに近い概念です。プロトコルに指定されている関数を定義することで、特定の型に対しての振る舞いを決定することが出来ます。
defprotocol AsAtom do def to_atom(data) end
これでAsAtomというプロトコルを作成しました。合わせて、AsAtomはto_atom(data)という関数を定義する必要があるということを表しています。あとはAsAtomの定義をもとに、それぞれの型に対して振る舞いを実装していきます。例えば、Atomのデータ構造に対してAsAtomプロトコルの振る舞いを定義するにはdefimpl AsAtom, for: Atom doと記述します。
defimpl AsAtom, for: Atom do def to_atom(atom), do: atom end defimpl AsAtom, for: BitString do defdelegate to_atom(string), to: String end defimpl AsAtom, for: List do defdelegate to_atom(list), to: List end defimpl AsAtom, for: Map do def to_atom(map), do: List.first(Map.keys(map)) end
上記のコードはElixir Schoolから抜粋しました。
Elixir Schoolのコードをもとに、Intergerに対してオリジナルの定義をしてみました。Interger型の値を受け取った場合は必ず0を返すようにします。
defimpl AsAtom, for: Integer do def to_atom(map), do: 0 end
実行してみます。
import AsAtom to_atom(111) |> IO.puts() # 0
実装が反映されていることが確認できました。プロトコルはいわゆるポリモーフィズムの1つであり、3つあるポリモーフィズムのうちのアドホック多相に該当するとのことです。ポリモーフィズムにも3つの種類があるというのは全く知りませんでした...。
先生詳しすぎます...👨🏫
Enumerableプロトコル🧪
プロトコルについて理解が深まったところで、最後にEnumerableプロトコルについて追っていきます。Enumerableはenum.exのファイル内に実は定義されています。なんとファイルの一番上に定義されていました。
# 簡単のため@moduledocなどは削除してあります defprotocol Enumerable do def reduce(enumerable, acc, fun) def count(enumerable) def member?(enumerable, element) def slice(enumerable) end
Enumerableプロトコルは上記4つの関数を定義してあげる必要があります。何とこの4つを定義することでEnumモジュールに定義されている関数のほぼ全てが使用可能になるというのです。Enumモジュールに定義されている関数の多くはこのEnumerable.reduce/count/member?/sliceによって実装されているのです。非常によく設計されています。恐るべしEnumモジュール...。
Listへの定義
一例としてListに対してEnumerableプロトコルがどのように定義されているか紹介しておきます。enum.exファイルのほぼ一番下に定義されているのを確認しました。
defimpl Enumerable, for: List do def count([]), do: {:ok, 0} def count(_list), do: {:error, __MODULE__} def member?([], _value), do: {:ok, false} def member?(_list, _value), do: {:error, __MODULE__} def slice([]), do: {:ok, 0, fn _, _ -> [] end} def slice(_list), do: {:error, __MODULE__} def reduce(_list, {:halt, acc}, _fun), do: {:halted, acc} def reduce(list, {:suspend, acc}, fun), do: {:suspended, acc, &reduce(list, &1, fun)} def reduce([], {:cont, acc}, _fun), do: {:done, acc} def reduce([head | tail], {:cont, acc}, fun), do: reduce(tail, fun.(head, acc), fun) @doc false def slice(_list, _start, 0, _size), do: [] def slice(list, start, count, size) when start + count == size, do: list |> drop(start) def slice(list, start, count, _size), do: list |> drop(start) |> take(count) defp drop(list, 0), do: list defp drop([_ | tail], count), do: drop(tail, count - 1) defp take(_list, 0), do: [] defp take([head | tail], count), do: [head | take(tail, count - 1)] end
先程、紹介した4つの関数が定義されています。何やらそれぞれの関数がタプルを返していますが、これはStream型のデータに対応するための記述だそうです。Streamは遅延のEnumとして定義されているとドキュメントに記載がありました。
Streams are composable, lazy enumerables
今回はタプルの返す値の意味については割愛しますが、Enumerableプロトコルに定義された4つの関数全てが定義されているのが確認出来ます。そしてこの4つの関数によってEnumモジュールに定義されている関数のほぼ全てを使うことが出来るのです。
まとめ📖
Enumモジュールを掘り下げていくことでどのように作られているのかが分かりました。
Enumはモジュールであり関数をまとめたものEnumモジュールはプロトコルを使って実装されている- プロトコルとは振る舞いを定義したインターフェースのようなもので、型に対して定義する
Enumerableプロトコルはreduce/count/member?/sliceの4つの関数を定義する必要がある- 4つの関数を定義することで、
Enumモジュールに定義されている関数をほぼ全て使うことが出来る
普段、自分が使っている言語の仕組みが分かると非常に面白いですね。
中々、一人では挫折してしまうような内容ですが、皆さんの知識を総動員して掘り下げていった結果、Enumモジュールを完全に理解した状態になれました。
好評でしたら、次は別のモジュールなどを掘り下げていこうと思います。


")







