業務で集計処理を書く予定があるのですが、サブクエリとLEFT JOINのどちらを使って集計した方が良いのかを判断できませんでした。もちろん、データ量やデータ特性、トレードオフなどを踏まえて判断する必要がありますが、今後、同じような場面に遭遇した際にデファクトスタンダートとなるのはどちらかなのかをハッキリとさせておきたいです。
世の中には「推測するな。計測せよ」という言葉があるので、実際にサブクエリとLEFT JOINでそれぞれ集計処理を計測してみました。
結果的に今回のパターンではLEFT JOINの方がパフォーマンスが良かったです。
では、詳しく紹介していきます。
テーブル定義
以下のようなテーブルがあったとします。
ユーザーはポストを任意の数だけ投稿できるように、中間テーブルuser_postsを定義しています。
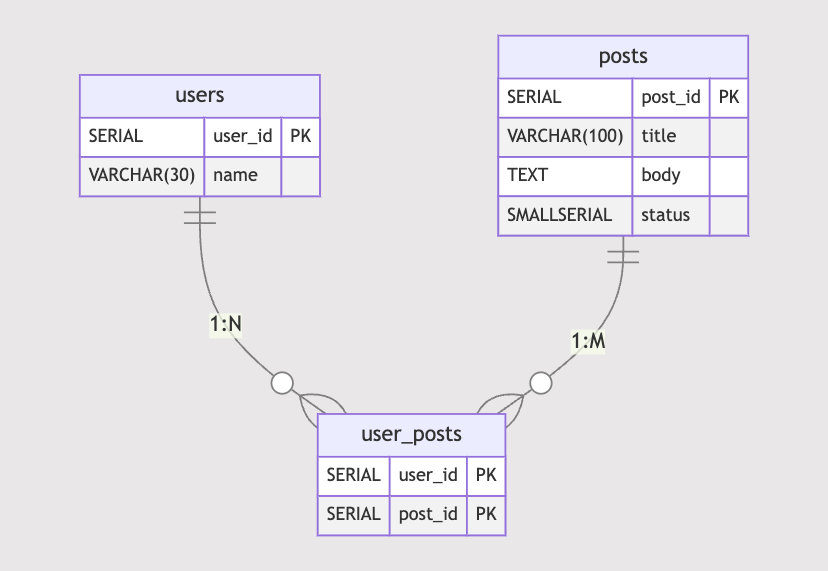
PRIMARY KEYの設定のよる自動で作成されるインデックス以外にpostsテーブルにはpost_idとstatusの複合インデックスを定義しています。
これはpost_idとstatusによる絞り込みが同時にされることを想定しているため、一般的なアプリケーションでも同じようなインデックスが作成されるだろう...という仮定を元に定義しました。
今回、検証するのは「ユーザーごとに各ステータスのポスト数をカウントする」という集計処理です。
postsが持つstatusには下書き(0)、公開中(1)、非公開中(2)の3種類があるので、以下のような集計結果になります。
| user_id | 下書きの総数 | 公開中の総数 | 非公開中の総数 |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 2 | 0 | 2 | 1 |
| 3 | 0 | 3 | 0 |
集計SQL
サブクエリ ver.
SELECT句で各ステータスに対応するCOUNT句をサブクエリを使って集計をします。
※記事上での見やすさのため、ワンライナーで記述してあります。
SELECT up.user_id, (SELECT COUNT(post_id) FROM posts WHERE status = 0 AND post_id IN (SELECT post_id FROM user_posts WHERE user_id = up.user_id)) AS 下書きの総数, (SELECT COUNT(post_id) FROM posts WHERE status = 1 AND post_id IN (SELECT post_id FROM user_posts WHERE user_id = up.user_id)) AS 公開中の総数, (SELECT COUNT(post_id) FROM posts WHERE status = 2 AND post_id IN (SELECT post_id FROM user_posts WHERE user_id = up.user_id)) AS 非公開中の総数 FROM user_posts AS up GROUP BY up.user_id ORDER BY up.user_id ;
LEFT JOIN ver.
あらかじめLEFT JOINしたテーブルをSUMとCASEを使って集計します。
SELECT up.user_id, SUM(CASE WHEN status = 0 THEN 1 ELSE 0 END) AS 下書きの総数, SUM(CASE WHEN status = 1 THEN 1 ELSE 0 END) AS 公開中の総数, SUM(CASE WHEN status = 2 THEN 1 ELSE 0 END) AS 非公開中の総数 FROM user_posts AS up LEFT OUTER JOIN posts ON up.post_id = posts.post_id GROUP BY up.user_id ORDER BY up.user_id ;
計測結果
上記2つの集計クエリをEXPLAIN ANALYZEを使って計測します。
ユーザー1人に対して3つのポストを作成しておりstatusはランダムです。
また、データ数によって結果が変わるかもしれないのでユーザー数を100, 1000, 10000の場合に、それぞれを計測しています。
以下のSQLを使ってテーブル・データ作成を行いました。
※データ数の表示: (ユーザー数:ポスト数)
| 集計方法 | 項目名 | 100:300 | 1000:3000 | 10000:30000 |
|---|---|---|---|---|
| LEFT JOIN | Planning Time | 0.413ms | 0.452ms | 0.537ms |
| Execution Time | 0.667ms | 4.181ms | 57.074ms | |
| サブクエリ | Planning Time | 2.626ms | 0.94ms | 0.892ms |
| Execution Time | 25.883ms | 25.398ms | 186.85ms |
考察
全体的に見て明らかにサブクエリが遅いことが分かります。
ユーザー数が100と1000の計測値がほとんど変化していないので、データ量にあまり依存しないのかな?と感じたのですが、ユーザ数が10000の場合に明らかなパフォーマンス悪化が発生しました。ユーザー数が1000の場合でもLEFT JOINよりも遅いので、あえてサブクエリを採用する理由はないでしょう。
一方でLEFT JOINはやはりデータ量に依存して、パフォーマンスが悪化していきます。
100と1000の場合ですでに6倍近い変化があるので、データ量が10万・100万...と増えていくケースは工夫が必要かもしれません。とはいえ、今回の集計処理においてはLEFT JOINに軍配が上がります。
実行計画を見てみる
ユーザー数が100の場合に出力された実行計画です。
サブクエリの方は行数が多いので、折りたたんであります。
サブクエリ
QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------- Group (cost=0.15..4163.46 rows=100 width=28) (actual time=0.456..32.357 rows=100 loops=1) Group Key: up.user_id -> Index Only Scan using user_posts_pkey on user_posts up (cost=0.15..18.96 rows=300 width=4) (actual time=0.018..0.251 rows=300 loops=1) Heap Fetches: 300 SubPlan 1 -> Aggregate (cost=13.81..13.82 rows=1 width=8) (actual time=0.110..0.110 rows=1 loops=100) -> Hash Join (cost=5.79..13.81 rows=1 width=4) (actual time=0.078..0.105 rows=1 loops=100) Hash Cond: (posts.post_id = user_posts.post_id) -> Seq Scan on posts (cost=0.00..7.75 rows=103 width=4) (actual time=0.003..0.051 rows=103 loops=100) Filter: (status = 0) Rows Removed by Filter: 197 -> Hash (cost=5.75..5.75 rows=3 width=4) (actual time=0.036..0.036 rows=3 loops=100) Buckets: 1024 Batches: 1 Memory Usage: 9kB -> Seq Scan on user_posts (cost=0.00..5.75 rows=3 width=4) (actual time=0.018..0.033 rows=3 loops=100) Filter: (user_id = up.user_id) Rows Removed by Filter: 297 SubPlan 2 -> Aggregate (cost=13.84..13.85 rows=1 width=8) (actual time=0.103..0.103 rows=1 loops=100) -> Hash Join (cost=5.79..13.83 rows=1 width=4) (actual time=0.076..0.101 rows=1 loops=100) Hash Cond: (posts_1.post_id = user_posts_1.post_id) -> Seq Scan on posts posts_1 (cost=0.00..7.75 rows=113 width=4) (actual time=0.002..0.050 rows=113 loops=100) Filter: (status = 1) Rows Removed by Filter: 187 -> Hash (cost=5.75..5.75 rows=3 width=4) (actual time=0.035..0.035 rows=3 loops=100) Buckets: 1024 Batches: 1 Memory Usage: 9kB -> Seq Scan on user_posts user_posts_1 (cost=0.00..5.75 rows=3 width=4) (actual time=0.018..0.033 rows=3 loops=100) Filter: (user_id = up.user_id) Rows Removed by Filter: 297 SubPlan 3 -> Aggregate (cost=13.76..13.77 rows=1 width=8) (actual time=0.102..0.102 rows=1 loops=100) -> Hash Join (cost=5.79..13.76 rows=1 width=4) (actual time=0.081..0.099 rows=1 loops=100) Hash Cond: (posts_2.post_id = user_posts_2.post_id) -> Seq Scan on posts posts_2 (cost=0.00..7.75 rows=84 width=4) (actual time=0.002..0.049 rows=84 loops=100) Filter: (status = 2) Rows Removed by Filter: 216 -> Hash (cost=5.75..5.75 rows=3 width=4) (actual time=0.037..0.037 rows=3 loops=100) Buckets: 1024 Batches: 1 Memory Usage: 9kB -> Seq Scan on user_posts user_posts_2 (cost=0.00..5.75 rows=3 width=4) (actual time=0.020..0.035 rows=3 loops=100) Filter: (user_id = up.user_id) Rows Removed by Filter: 297
LEFT JOIN
QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------- Sort (cost=26.12..26.37 rows=100 width=28) (actual time=0.413..0.421 rows=100 loops=1) Sort Key: up.user_id Sort Method: quicksort Memory: 32kB -> HashAggregate (cost=21.80..22.80 rows=100 width=28) (actual time=0.333..0.354 rows=100 loops=1) Group Key: up.user_id Batches: 1 Memory Usage: 32kB -> Hash Left Join (cost=10.75..16.55 rows=300 width=6) (actual time=0.134..0.233 rows=300 loops=1) Hash Cond: (up.post_id = posts.post_id) -> Seq Scan on user_posts up (cost=0.00..5.00 rows=300 width=8) (actual time=0.014..0.042 rows=300 loops=1) -> Hash (cost=7.00..7.00 rows=300 width=6) (actual time=0.112..0.113 rows=300 loops=1) Buckets: 1024 Batches: 1 Memory Usage: 20kB -> Seq Scan on posts (cost=0.00..7.00 rows=300 width=6) (actual time=0.006..0.056 rows=300 loops=1)
シンプルにサブクエリの方が必要なステップが多いようです。
絞り込んでいるstatusの値が違うだけなので、共通部分はいい感じに実行をまとめてくれているのかと思っていたのですが、考えが甘かったです。Seq Scanがされている箇所がいくつかありますが、どれもHash Condの処理の一部として実行されています。Seq Scanだからパフォーマンスが悪いんじゃ...と思ってしまいますが、以前の記事にも書いたように結合を高速化するためにインデックスを作成するべきではありません。
ということで、今回のような集計処理であればLEFT JOINを選択するのが良さそうです。
少しでも「ええな〜」と思ったらはてなスター・はてなブックマーク・シェアを頂けると励みになります。