データベースで0対Nのモデルを表現する際に、よく外部キー制約とNULL許容の制約を定義することがあります。
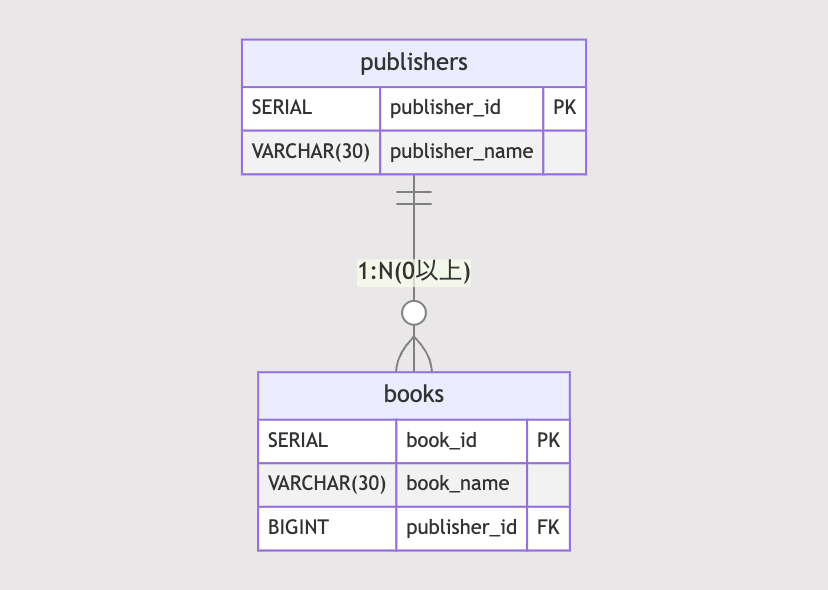
値は特定のテーブルのIDもしくはNULLのどちらかを持つことになります。これを出版社(publishers)と書籍(books)のモデルをテーブルに落とし込んでみると以下のようになります。
基本的に書籍は出版社から出版されてbooksテーブルのレコードはpublisher_idで紐付けられますが、個人出版・データベースに登録されていない出版社から出版された書籍はpublisher_idにNULLを持つこととします。別途、個人か企業による出版かのカラムを持たせたり...と考えられることはありますが、今回は簡単のために省略します。
しばしば出版社がどんな書籍を出版しているのかを検索したいため、books.publishers_idに検索用のインデックスを作成します。
このインデックスは出版社から出版されている書籍に対して、検索の高速化を期待してのものですが、果たして個人出版の書籍の絞り込み(books.publishers_idがNULL)に対しても有効なのでしょうか。
NULLを含むカラムを検索するということは一般的なことだと思いますが、意外にも深く考えたことがなかったテーマです。
事前の予測ではインデックスが効いてくれると思いますが、実際に検証してみたいと思います。
用意するデータ
出版社(publishsers)と書籍(books)の2つのテーブルを定義します。
またbooksにはpublishers_idに単一インデックスを作成しておきます。books.publishers_idは外部キー制約を持ちつつNULLを許可しています。
BEGIN; CREATE TABLE IF NOT EXISTS publishers ( publisher_id SERIAL PRIMARY KEY, publisher_name VARCHAR(30) NOT NULL ); CREATE TABLE IF NOT EXISTS books ( book_id SERIAL PRIMARY KEY, book_name VARCHAR(30) NOT NULL, publisher_id BIGINT NULL, FOREIGN KEY (publisher_id) REFERENCES publishers(publisher_id) MATCH FULL ); CREATE INDEX books_publisher_id ON books (publisher_id); COMMIT;
postgres=# \d books
Table "public.books"
Column | Type | Collation | Nullable | Default
--------------+-----------------------+-----------+----------+----------------------------------------
book_id | integer | | not null | nextval('books_book_id_seq'::regclass)
book_name | character varying(30) | | not null |
publisher_id | bigint | | |
Indexes:
"books_pkey" PRIMARY KEY, btree (book_id)
"books_publisher_id" btree (publisher_id)
Foreign-key constraints:
"books_publisher_id_fkey" FOREIGN KEY (publisher_id) REFERENCES publishers(publisher_id)
定義したテーブルに適当なデータを作成します。
publishersとbooksそれぞれにデータを100件ずつ作成して、1社が1つの書籍を出版している状態にしました。
あとは個人出版の書籍データを10件ほど追加しました。
BEGIN; INSERT INTO publishers (publisher_name) SELECT substring(md5(random()::text) from 1 for 10) FROM generate_series(1, 100); INSERT INTO books (book_name, publisher_id) SELECT substring(md5(random()::text) from 1 for 10), s.a FROM generate_series(1, 100) AS s(a); INSERT INTO books (book_name, publisher_id) SELECT substring(md5(random()::text) from 1 for 10), null FROM generate_series(1, 10); COMMIT;
検証するSQL
以下、2つのシンプルな絞り込みのクエリをEXPLAINで実行計画を検証します。
SELECT * FROM books WHERE books.publisher_id IS NULL; SELECT * FROM books WHERE books.publisher_id = 1;
検証結果
まずデータ数が100件の場合では、どちらもインデックスが使用されずSeqScanになりました。
十分なデータ量がないためインデックスを使用するよりもフルスキャンした方が効率が良いと判断されたようです。
これではNULL値を含むカラムに対してインデックスが有効なのか判断ができないので、データ数を増やして再度、検証してみます。
データ数が100件の場合
postgres=# EXPLAIN SELECT * FROM books WHERE books.publisher_id IS NULL; QUERY PLAN ------------------------------------------------------- Seq Scan on books (cost=0.00..2.10 rows=10 width=23) Filter: (publisher_id IS NULL) (2 rows) postgres=# EXPLAIN SELECT * FROM books WHERE books.publisher_id = 1; QUERY PLAN ------------------------------------------------------ Seq Scan on books (cost=0.00..2.38 rows=1 width=23) Filter: (publisher_id = 1) (2 rows)
データ数が1,000件の場合
データを1,000件にした所でインデックスが使用されていることが分かりました。
当初の想定通り、IS NULLの検索でもpublishers_idの絞り込みと同じようにインデックスが使用されていることが分かります。
postgres=# EXPLAIN SELECT * FROM books WHERE books.publisher_id IS NULL; QUERY PLAN ------------------------------------------------------------------------------------ Index Scan using books_publisher_id on books (cost=0.28..10.81 rows=145 width=23) Index Cond: (publisher_id IS NULL) (2 rows) postgres=# EXPLAIN SELECT * FROM books WHERE books.publisher_id = 1; ; QUERY PLAN --------------------------------------------------------------------------------- Index Scan using books_publisher_id on books (cost=0.28..8.29 rows=1 width=23) Index Cond: (publisher_id = 1) (2 rows)
ちなみにNOT IS NULLでは当然、インデックスが使用されません。
postgres=# EXPLAIN SELECT * FROM books WHERE books.publisher_id IS NOT NULL; QUERY PLAN ---------------------------------------------------------- Seq Scan on books (cost=0.00..18.00 rows=1000 width=23) Filter: (publisher_id IS NOT NULL) (2 rows)
NULLのカラムにインデックスが効くということはインデックス(B-tree)にNULLのカラムの情報が記録されているということです。
調べてみた所、PostgreSQLではNULLをインデックスの最後に記録しているようです。このおかげでNULLに対してインデックスが効くというわけですね。
ただNULLをB-tree上で表現するとどうなるのでしょうか。
(NULL, pointer)のような構造だとNULL重複してしまうため、NULLを持つカラムが複数ある場合にパフォーマンスが悪化しそうです。(id, NULL, pointer)のような構造を持っていれば、パフォーマンスの悪化は発生しないでしょう。
NULLのレコードを多い場合の検証
ということでNULL値を持つレコードを増やして同じ条件下で実行計画を見てみます。
books.publishers_idがNULLではないレコードとNULLのレコードを合わせて2,000件、用意して比率を変えながら検証してみました。
全ての結果を記載すると量が多くなってしまうので、特に面白い結果が現れたケースを紹介します。NULLのデータが1,500の場合に実行計画でBitmap Heap Scanが選択されました。
postgres=# EXPLAIN SELECT * FROM books WHERE books.publisher_id IS NULL; QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on books (cost=4.31..13.42 rows=4 width=90) Recheck Cond: (publisher_id IS NULL) -> Bitmap Index Scan on books_publisher_id (cost=0.00..4.31 rows=4 width=0) Index Cond: (publisher_id IS NULL) (4 rows)
Bitmap Heap Scanはカーディナリティー(値の種類)が低い場合に、効果を発揮するスキャン方法です。
つまりNULL値が多い場合はインデックスをそのまま使用するよりも一度、Bitmapを作成してから絞り込んだ方がパフォーマンスが良いだろうと判断されたということです。
NULL値を持つレコードが多い場合にパフォーマンス悪化が発生するのではないかと思いましたが、回避方法はあるみたいですね。
Bitmap Scanについて詳しく解説している過去の記事
Bitmap Heap Scanが選択された理由がカラムのカーディナリティーが低いと判断されたからなのか、インデックスのデータ構造では不都合があったからなのかまでは分かりませんでした。詳しい方がいれば教えてください。
まとめ
NULLのカラムに対してもインデックスは効くNULL値はデフォルトでインデックスの最後に記録されているNULLが極端に増えても明らかな検索パフォーマンスの悪化は発生しなかったBitmap Heap Scanはカラムのカーディナリティーが小さい場合に有効なスキャン方法NULLが極端に多い場合にはBitmap Heap Scanが選択された
ただのシンプルな絞り込みをテーマにしたつもりですが非常に奥深かったです。
とりあえずNULLのカラムに対してもインデックスが効くことが分かったので安心してクエリを発行することができます。
少しでも「ええな〜」と思ったらはてなスター・はてなブックマーク・シェアを頂けると励みになります。