データベースの設計において正規化の結果、中間テーブルを作ることがよくあると思います。
以下のようなテーブル群があったとします。登録されたユーザーと登録された商品を誰が出品した商品なのかを中間テーブルへ記録しています。
- users
- products
- user_products(中間テーブル)
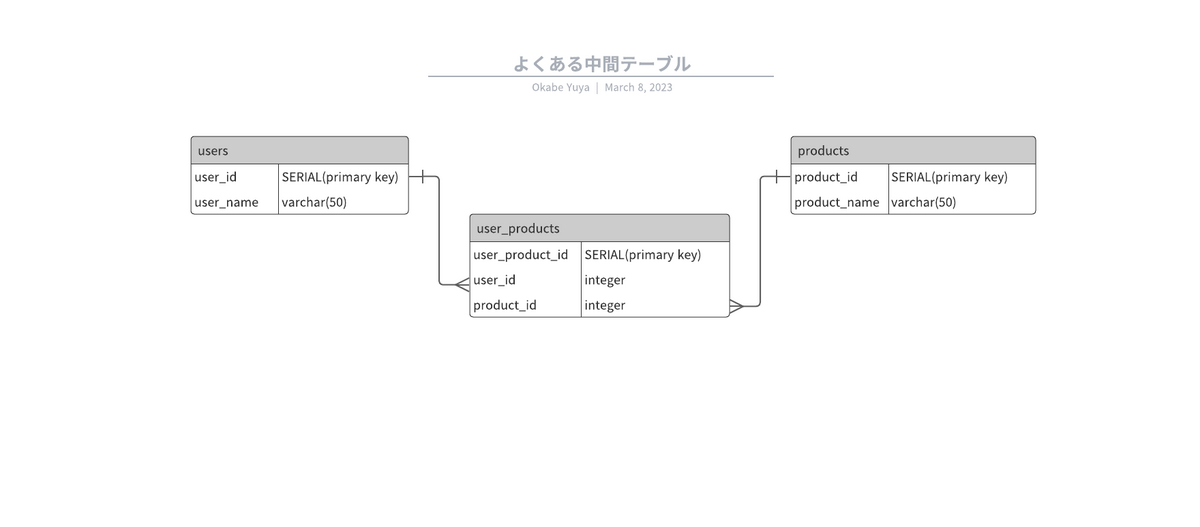
中間テーブルuser_productsにインデックスを作成する場合、3つの方法が考えられます。
- A:
user_idとproudct_idに対してそれぞれ単一インデックスを作成する - B:
user_idとproduct_idの複合インデックスを作成する - C: AとBの合わせ技
インデックスの作成方法はAとBのどちらが良いのでしょうか。
Railsでuser_productsのような中間テーブルを作成して、user_idとproduct_idに外部キー制約を付与すると、それぞれに単一のインデックスが作成されます。
create_table :user_products do |t| t.references :user, foreign_key: true t.references :product, foreign_key: true t.timestamps end
確証はないのですが「複合インデックスの方が、いいんじゃないの?」と思ってしまいます。
user_productsが参照されるストーリーを考えると、出品された商品の一覧にユーザーと商品情報をつけ合わせたデータが必要になるケースが考えられます。その際にはuser_productsにJOINを行う必要があるためuser_idとproduct_id両方のキーを使うことになります。
...と推測ばかりしていてもしょうがないので、実際に計測してみます。
使用するデータについて
先ほど紹介したER図に基づいて3つのテーブルを作成し、それぞれに1万件ずつデータを投入します。
データの分布によって計測結果が変わる可能性がありますが、今回は考慮しません。
例: user_productsに作成されたデータ
postgres=# SELECT * FROM user_products LIMIT 1; user_product_id | user_id | product_id -----------------+---------+------------ 1 | 1 | 1 (1 row)
計測するSQLと条件
3つのSQLをEXPLAIN ANALYZEを使用して計測します。
Indexの状態
- インデックスなし
- 単一インデックス
- 複合インデックス
- 単一と複合インデックス
計測結果
実行速度
EXPLAIN ANALYZEを実行して表示されたExecution Timeの値です。
平均的にみると複合インデックスを作成した場合が最もパフォーマンスが良いことが分かります。WHEREのみの場合に圧倒的な速度を叩き出しています。
| A: JOINのみ | B: JOIN+WHERE | C: WHEREのみ | |
|---|---|---|---|
| インデックスなし | 14.326ms | 3.136 ms | 1.840 ms |
| 単一インデックス | 14.117 ms | 1.407 ms | 4.653 ms |
| 複合インデックス | 6.873 ms | 4.750 ms | 0.060 ms |
| 単一と複合インデックス | 12.599 ms | 5.321 ms | 4.121 ms |
実行計画
インデックスなしの場合には当然ですが、全ケースでSeqScanされてしまいました。
面白いのはどのインデックスを作成した場合でもSeqScanとIndexScanの両方が使用されるという点です。
| A: JOINのみ | B: JOIN+WHERE | C: WHEREのみ | |
|---|---|---|---|
| インデックスなし | SeqScan | SeqScan | SeqScan |
| 単一インデックス | SeqScan | SeqScanとIndexScan | IndexScan |
| 複合インデックス | SeqScan | SeqScanとIndexScan | IndexScan |
| 単一と複合インデックス | SeqScan | SeqScanとIndexScan | IndexScan |
複合インデックスを作成した場合にJOINのみを実行すれば、複合インデックスが使われてくれるのかと期待していましたが、そうはなりませんでした。
QUERY PLAN --------------------------------------------------------------------------------------------------------------------------------- Hash Join (cost=588.00..795.52 rows=10000 width=61) (actual time=3.446..6.453 rows=10000 loops=1) Hash Cond: (up.product_id = p.product_id) -> Hash Join (cost=289.00..470.26 rows=10000 width=35) (actual time=1.452..3.239 rows=10000 loops=1) Hash Cond: (up.user_id = u.user_id) -> Seq Scan on user_products up (cost=0.00..155.00 rows=10000 width=12) (actual time=0.007..0.480 rows=10000 loops=1) -> Hash (cost=164.00..164.00 rows=10000 width=23) (actual time=1.408..1.408 rows=10000 loops=1) Buckets: 16384 Batches: 1 Memory Usage: 674kB -> Seq Scan on users u (cost=0.00..164.00 rows=10000 width=23) (actual time=0.006..0.560 rows=10000 loops=1) -> Hash (cost=174.00..174.00 rows=10000 width=26) (actual time=1.939..1.939 rows=10000 loops=1) Buckets: 16384 Batches: 1 Memory Usage: 704kB -> Seq Scan on products p (cost=0.00..174.00 rows=10000 width=26) (actual time=0.012..0.732 rows=10000 loops=1) Planning Time: 11.842 ms Execution Time: 6.873 ms (13 rows)
しかし、JOIN+WHEREを実行すると作成した複合インデックスが使われました。
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
-----------------
Nested Loop (cost=0.57..197.72 rows=1 width=61) (actual time=4.030..4.708 rows=1 loops=1)
-> Nested Loop (cost=0.29..197.31 rows=1 width=35) (actual time=3.953..4.629 rows=1 loops=1)
-> Seq Scan on users (cost=0.00..189.00 rows=1 width=23) (actual time=0.638..1.310 rows=1 loops=1)
Filter: ((user_name)::text = 'ユーザーNo.5000'::text)
Rows Removed by Filter: 9999
/* 複合インデックスが使われていることが分かる */
-> Index Scan using user_products_multiple_idx on user_products up (cost=0.29..8.30 rows=1 width=12) (actual time=3.304..3.306
rows=1 loops=1)
Index Cond: (user_id = users.user_id)
-> Index Scan using products_pkey on products (cost=0.29..0.35 rows=1 width=26) (actual time=0.068..0.068 rows=1 loops=1)
Index Cond: (product_id = up.product_id)
Filter: ((product_name)::text = 'プロダクトNo.5000'::text)
Planning Time: 0.365 ms
Execution Time: 4.750 ms
(12 rows)
他の結果は行数が多いため、gistにて公開しています。気になる方は覗いてみてください。
中間テーブルに対して作成したインデックスの種類による実行結果 · GitHub
考察
何よりも驚いたのは単一インデックス、複合インデックスそれぞれのケースでJOINのみを実行してもHash Joinが選択されてハッシュテーブル作成のためにSeqScanが実行されるという点です。
今回は結合に使用するキーに対してインデックスを作成していたので何かしらの形で使われてるのかと思ったのですが、実際はそうではありませんでした。インデックスは結合時にも使われるものと思っていましたが、改めて調べてみたら「使われることもある」というのが正しいようでした。
重要
結合述語にインデックスを作成しても、ハッシュ結合のパフォーマンスは良くなりません。
記事の中にあるように、そもそも結合の高速化のためにインデックスを作成するという考え方が間違っていました。インデックスを使わずに実行されるHashJoinが遅いという自分の認識も明らかな誤認でした。
また、JOIN+WHEREを実行した際にはNestedLoopが選択されてデータの絞り込みが行われた後に、それぞれ単一インデックス・複合インデックスを参照してデータの参照が行われています。こちらではインデックスが想定通り使われていることが分かります。ただし、実行計画を見る限り単一インデックス・複合インデックスで大きな差がないことも分かりました。
結論
今回の計測結果から、中間テーブルには単一インデックス、複合インデックスどちらを作成するかはJOINの高速化を目的にするのではなく、WHERE句による絞り込みを高速化したい際に検討するのが良さそうです。単一インデックスと複合インデックスのどちらが良いかという問題ではなく、ユースケースに合わせてベターなものを選択する必要があります。データ量やデータ分布にも当然、依存します。
そもそも、SQLアンチパターンにもあるように中間テーブルにわざわざuser_product_idを用意せずに、user_idとproduct_idの複合キーをプライマリーキーとして作成すれば良いですね。
CREATE TABLE IF NOT EXISTS user_products ( user_id INTEGER, product_id INTEGER, PRIMARY KEY(user_id, product_id), FOREIGN KEY (user_id) REFERENCES users(user_id), FOREIGN KEY (product_id) REFERENCES products(product_id) );
postgres=# \d user_products
Table "public.user_products"
Column | Type | Collation | Nullable | Default
------------+---------+-----------+----------+---------
user_id | integer | | not null |
product_id | integer | | not null |
Indexes:
"user_products_pkey" PRIMARY KEY, btree (user_id, product_id) /* 複合インデックスが作成された */
:
IndexOnlyScanが選択されるようになりました。
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
-------------
Nested Loop (cost=0.57..193.72 rows=1 width=57) (actual time=0.668..1.292 rows=1 loops=1)
-> Nested Loop (cost=0.29..193.31 rows=1 width=31) (actual time=0.656..1.278 rows=1 loops=1)
-> Seq Scan on users u (cost=0.00..189.00 rows=1 width=23) (actual time=0.639..1.260 rows=1 loops=1)
Filter: ((user_name)::text = 'ユーザーNo.5000'::text)
Rows Removed by Filter: 9999
-> Index Only Scan using user_products_pkey on user_products up (cost=0.29..4.30 rows=1 width=8) (actual time=0.012..0.013 row
s=1 loops=1)
Index Cond: (user_id = u.user_id)
Heap Fetches: 0
:
少しでも「ええな〜」と思ったらイイネ!・シェア!・はてなブックマークを頂けると励みになります。