mixのプロジェクトの用意
前提としてmix newでプロジェクトが作成されている状態とします
mixコマンドを使ってプロジェクトを作成するまでの手順は
こちらの前半部分で触れていますので
必要であればご覧ください
テキトーにgitを覗いてみる
あった(秒速
リポジトリ名見ただけで分かりましたわ
starもかなりあるのでこちらのcsvモジュールを使用します
ライブラリのダウンロード
READ.MEに従いmix.exsファイルに
{:csv, "~> 2.3"}
を追記します
./project_name/mix.exs
defp deps do [ # {:dep_from_hexpm, "~> 0.3.0"}, # {:dep_from_git, git: "https://github.com/elixir-lang/my_dep.git", tag: "0.1.0"} {:csv, "~> 2.3"} #2019/04/06時のREAD.MEを参照 ] end
あとはいつものように
$ mix deps.get $ mix deps.compile #やらなくてもok
コマンドを叩いてライブラリをダウンロードしましょう
これでcsvライブラリを使う準備はできました
csvモジュールの使い方
ざっくりとREAD.MEを見た感じ、decodeとencodeに対応しているようです
今回はcsvファイルへの書き込みなのでencode部分のみを取り扱います
どんなデータを用意すればいいのかという話になりますがREAD.MEに記述あります
Encoding
Do this to encode a table (two-dimensional list):
table_data |> CSV.encode
二次元のリスト用意して、パイプでencodeすればええでーってことですね
今回もテキトーなデータ用意しました。らきすたは初めてハマったアニメです
このデータをcsv形式で書き出してみます
[ ["name", "class", "height", "food"], ["泉こなた", "2年E組", "142", "チョココロネ"], ["柊つかさ", "2年E組", "158", "バルサミコ酢"], ["柊かがみ", "2年D組", "159", "ヨーグルト"], ["高良みゆき", "2年E組", "166", "うなぎの卵焼き"], ]
READ.MEに従い記述
lst_data |> CSV.encode
あー、でもこれだけだとファイルは生成されません
ファイル読み込みと書き込みの操作と追記します
ついでに関数化しておきましょう
defmodule ProjectCSV do def output_csv(file_name) do lst_data = [ ["name", "class", "height", "food"], ["泉こなた", "2年E組", "142", "チョココロネ"], ["柊つかさ", "2年E組", "158", "バルサミコ酢"], ["柊かがみ", "2年D組", "159", "ヨーグルト"], ["高良みゆき", "2年E組", "166", "うなぎの卵焼き"], ] file = File.open!(file_name, [:write, :utf8]) lst_data |> CSV.encode |> Enum.each(&IO.write(file, &1)) IO.puts("--> output csv file") end end
本来ならファイル名と共に2次元リストも引数として渡すべきですが
今回は関数内に変数を置いてます
さっそくこいつが上手く動くかを確かめてみます
iex -S mix
mix deps.compileをしていなければライブラリのコンパイルが始まります
iex > ProjectCSV.output_csv("lucky_star.csv")
--> output csv file
:ok
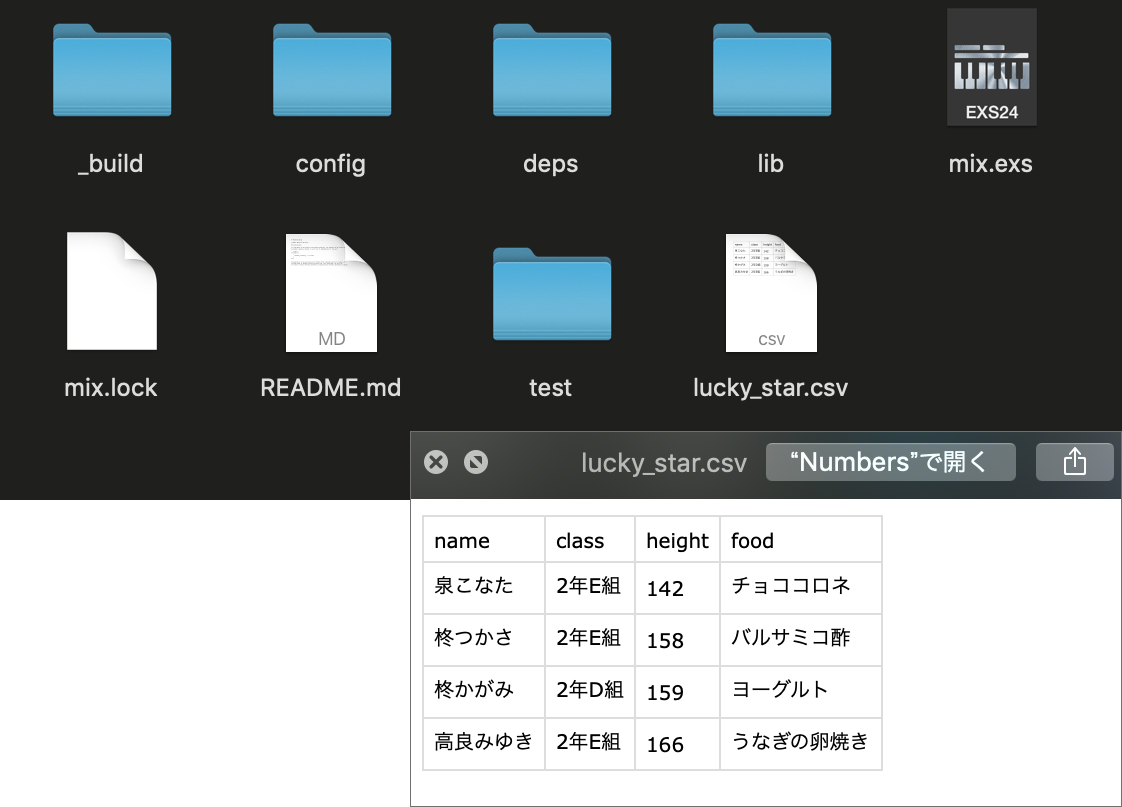
今回は特にパスで出力先を指定しないのでプロジェクトディレクトリの直下にcsvファイルが生成されます
お、無事に生成されました!!!
おまけ
同一のcsvにデータを追記していく場合には上のサンプルでは毎度上書きされてしまいます
csvモジュールの話ではないですが、同一のcsvファイルに追記していきたい場合には
optionのパラメータの:writeを:appendに変更します
#変更前 file = File.open!(file_name, [:write, :utf8]) #変更後 file = File.open!(file_name, [:append, :utf8])
:appendに変更してもう一度実行すると同じデータが追記されます
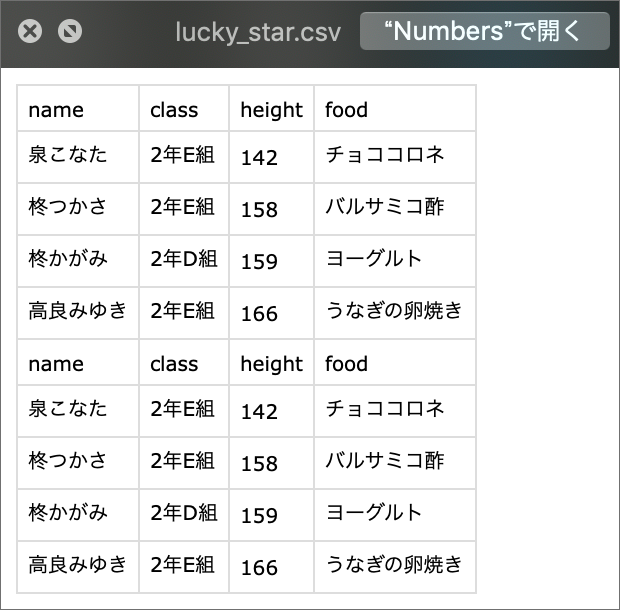
あら^〜、headerが2回も書き込まれている...
公式ドキュメントをみた感じpandasみたいにheaderをセットする引数はなさそう
ファイル読み込み時に対象のheaderが存在しているかをチェックしつつ
headerを挿入するかどうかという処理を組み込みます
def is_exist_header_in_file(file_name, header) do read_file = File.stream!(file_name) |> CSV.decode! |> Enum.to_list List.first(read_file) === header end
この関数にcsvファイル名とheaderのリストを渡すことで対象のheaderが
存在するかしないかをbool値でreturnしてくれます
その戻り値をcaseで場合分けさせて
- trueであればheaderは追記しない
- falseであればheaderを追記
するようにoutput_csv関数を変更しました
defmodule ProjectCSV do def is_exist_header_in_file(file_name, header) do read_file = File.stream!(file_name) |> CSV.decode! |> Enum.to_list List.first(read_file) === header end def output_csv(file_name) do header = ["name", "class", "height", "food"] lst_data = [ ["泉こなた", "2年E組", "142", "チョココロネ"], ["柊つかさ", "2年E組", "158", "バルサミコ酢"], ["柊かがみ", "2年D組", "159", "ヨーグルト"], ["高良みゆき", "2年E組", "166", "うなぎの卵焼き"], ] file = File.open!(file_name, [:append, :utf8]) case is_exist_header_in_file(file_name, header) do true -> lst_data |> CSV.encode |> Enum.each(&IO.write(file, &1)) false -> List.insert_at(lst_data, 0, header) |> CSV.encode |> Enum.each(&IO.write(file, &1)) end IO.puts("--> output csv file") end end
上手くいきました!!
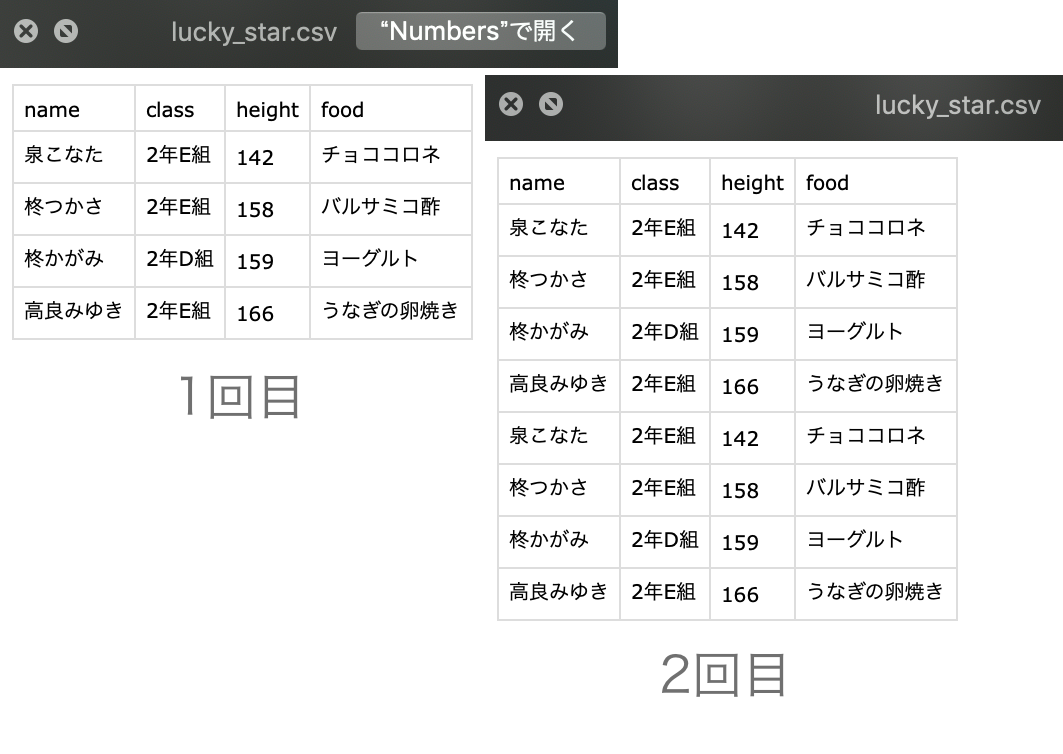
正直caseやなくてifでもええかなとは思う...
elixirではifを極力使わないようにした方がいいと偉い人が言っていました
関数でのパターンマッチもありだと今更思えてきた
