二分探索の生まれた背景
昇順ソート済みのリスト(配列)から特定の値のindex番号を取得したいとする
#8のindex番号はいくつ?(7が知りたい) item = 8 lst = [1,2,3,4,5,6,7,8,9,10]
これを単純に配列の頭から探索していくと
index番号の0から初めて7番目、すなわち8回目の試行で特定のindex番号を取得することができる
ここまで一見、何も問題が無いように思えるが、以下の場合を考えてみる
lst = [1,2,3,4, .... 10000000] item = 9999999
先ほどのように単純に配列の頭から探索をしたとすると最低でも9999999の試行が必要になる
あーなら、後ろから探索すればええんじゃないの?って思いますよね
後ろから探索した場合は2回の試行で終了です。やりました
では5000000を探したい場合はどうなるのか
頭からでも後ろからでも最低でも5000000の試行が必要になる
うわー、効率悪いね...となり生まれたのが二分探索です
二分探索の動き方
先ほども書いた通りにリストは昇順ソートされているとする
今回は
item = 3 lst = [1,2,3,4,5,6,7,8,9,10]
という条件で探索を行う

二分探索ではその名の通り、対象のリストを中心から2つに分割する
中心値を取得してそれ以下の数値をlst1に
中心値より大きな数値をlst2に分割する
今回の場合は少数は切り捨てられて以下のようになる
lst = [1,2,3,4,5,6,7,8,9,10] fetch_center_num = 5 lst1 = [1,2,3,4] lst2 = [6,7,8,9,10]
また取得した中心値が今回探索したい値(3)と等しいかをチェックする

今回の探索したい値(3)は5より小さいため、5以上の数値をもつlst2を破棄する
よって次はlst1に対して探索を行う
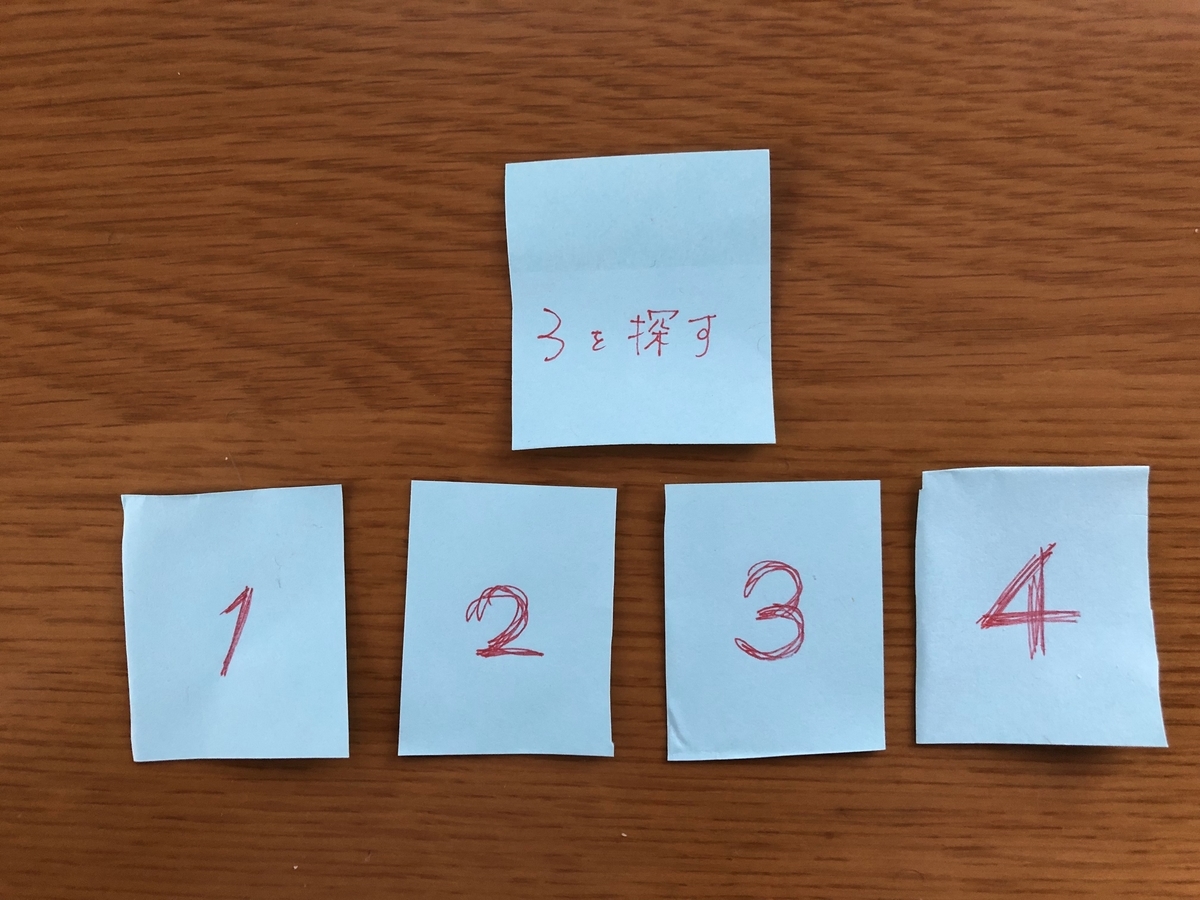
lst = [1,2,3,4] fetch_center_num = 2 lst1 = [1] lst2 = [3,4]
それでまた中心値を取得して同様に比較する
今回の中心値(2)は(3)より小さいため、2以下のの数値をもつlst1を破棄する

さらに同じことを繰り返す

中心値を取得して比較をする
今回の中心値が探索したい値と一致したため、試行を終了して
index番号を返す


見事(3)を見つけることが出来ました
この時点での試行回数は3回なので単純に探索するのとほぼ同じ試行回数となりました
二分探索での試行回数はn個の要素を持つリストの場合に log2 nとなります
つまりはn = 2 * numのnumを求めればOK
- 64個の要素をもつリストであれば6回
- 128 個の要素をもつリストであれば7回
- 1024個の要素をもつリストであれば10回
と要素が2倍になっても少ない回数で試行を終了することが可能
Elixirで書いてみる
とりあえず動くものが完成した
まずはbinary_search()をヘルパーとして使ってリストの長さを_binary_search()に渡している
あとは成否判定をプライベート関数のjudgeにやらせる
defmodule Algorithm do def binary_search(lst, item) do _binary_search(lst, 0, Enum.count(lst) -1, item) end defp _binary_search(lst, low, high, item) do mid = div(low + high, 2) value = Enum.at(lst, mid) if mid == Enum.count(lst) -1 and value != item do :not_found else judger(lst, low, high, item, mid, value) end end defp judger(_lst, _low, _high, item, mid, value) when value == item, do: mid defp judger(lst, low, _high, item, mid, value) when value > item, do: _binary_search(lst, low, mid-1, item) defp judger(lst, _low, high, item, mid, value) when value < item, do: _binary_search(lst, mid+1, high, item) end res = Algorithm.binary_search([1,3,4,5,6,7,23,56, 244,456], 5336) IO.puts(res) #not_found
しかし、bugを発見してしまった
これだと存在しない値をうまく発見できない場合がある
0や-4のようにリストの先頭値より小さな値を探索する場合に終了せずに無限ループしてしまう
簡易テストの結果
tests = [ Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], 1) == 0, Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], 3) == 2, Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], 10) == 9, Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], 15) == :error, Algorithm.binary_search([1,2,3,4,5,6,8,9,10], 7) == :error, Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], -10) == :error ] IO.inspect(tests) #どこかで無限ループして結果が表示されない
あと単純にコードがごちゃごちゃしてて可読性が悪い
ので、以下のように修正
defmodule Algorithm do def binary_search(lst, item) do _binary_search(lst, 0, Enum.count(lst) -1, item) end defp _binary_search(lst, low, high, item) do mid = div(low + high, 2) value = Enum.at(lst, mid) cond do value == item -> mid low == high -> :error value > item -> _binary_search(lst, low, mid-1, item) value < item -> _binary_search(lst, mid+1, high, item) end end end
発見できない場合の終了条件に以下を設定した
low == high
以下の場合を考えてみる
item = 999 lst = [1,2,3,4,5,6,7,8,9,10]
| 回数 | low | high |
|---|---|---|
| 1回目 | 0 | 10 |
| 2回目 | 5+1 | 10 |
| 3回目 | (10+5+1)/2 | 10 |
| 4回目 | (8+1+10)/2 | 10 |
| 5回目 | (9+1+10)/2 | 10 |
--> low == high になった
思った挙動をしているか再びテストをしておく
tests = [ Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], 1) == 0, Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], 3) == 2, Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], 10) == 9, Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], 15) == :error, Algorithm.binary_search([1,2,3,4,5,6,8,9,10], 7) == :error, Algorithm.binary_search([1,2,3,4,5,6,7,8,9,10], -10) == :error ] IO.inspect(tests) #result: #[true, true, true, true, true, true]
よさそうですね
最近、アルゴリズム組むの下手くそだなって思って勉強してますが
このコード書くだけで4時間ぐらいかかってしまった
pythonだとわりとすんなり書けるけど再帰だと頭をめちゃくちゃ使う
もっと短く出来るや、ここダメなんじゃね?という点がありましたら
ご指摘ください


