前回の話
「並行コンピューティング技法」を読み進める中で「並行和」の実装をElixirを用いて行なった。何とか実装が完了した並行和の処理を複数プロセスを立ち上げてチャンクを分割して実行する並行処理(parallel)と、チャンクを分割せずにメインの1つのプロセスのみで実行する逐次処理(serial)と比較した所、何と並行処理よりも逐次処理の方が約10000倍も速いという残念な結果に終わってしまった。完全敗北。
どうすればパフォーマンスが向上するか
この旨を呟いた所、Yamazakiさんよりアドバイスを頂きました。(いつも有難うございます🙇♂️)
あとEnum.chunk_every もお察し通り遅いです。
— Susumu Yamazaki (ZACKY) (@zacky1972) 2020年2月23日
なるほど...。プロセスの起動と終了がボトルネックになり得るとは...。
Elixirは気軽にプロセス生成が強みの1つであり、ユースケースの1つとして個人的に考えているのは「大量のデータをチャンクに分割し、チャンク毎に対応するプロセスを立ち上げて前処理をゴリゴリと行う」という使い方。しかしながら、プロセス生成がボトルネックになるというのは中々につらい。
逆に言えば、サーバー起動時に常駐のプロセスが立ち上がり、それぞれがタスクを担うような処理に向いているということにはなる。
今回は実際にプロセスの起動と終了の内、実行時のプロセス起動がどれだけパフォーマンスに影響を与えているかを確認するために、あらかじめプロセスをベンチマーク測定前に立ち上げた状態で並行和の処理を行うように前回のベンチマークを改良してみた。
ベンチマークの実装
(結果が気になる方はこの章はすっ飛ばしてください)
コードの全体像はこちら
github.com
プロセスを実行時前に立ち上げることによって様々な問題が発生することが実装を進める中で次々に発覚して、ほとんど新しく書き直すこととなった。まずベンチマークに使用する検証用データ同様にプロセスを立ち上げて得られるプロセスのPIDをモジュール変数に保持させておく必要がある。
defmodule Sample do @processes_pid [1,2,3....] end
この部分でかなりやられた。まず第一に今までプロセスの起動と実行終了結果を受け取るために使用してTaskが使用出来ないことが分かり、Elixirのmessage passingを利用してフルスクラッチで実装する方針を取った。(Taskが使えない理由についてはおまけにて解説)
そうなると必然的に、プロセス間でのmessage passingをコントロールする必要があるため、
- メインプロセス
- 実行結果を受け取る受信用のプロセス -> 全てのプロセスの終了を確認したらメインプロセスに結果を送信
- タスクを実行するN個(N -> データ数をチャンク数で割った数)のプロセス -> 終了次第、受信用プロセスに結果を送信
このように各プロセスの用意とmessageの定義をすることになった。詳しくは解説しないが、ざっくりとコードの核部分だけを見せておく。
受信用プロセスのための関数
./parallel_sum/lib/sum.ex
@doc """ 生成したプロセスによって算出した合計値を再帰関数のアキュムレーターに記録 """ def receiver(process_num, pid) do sum = _receiver(process_num, []) send(pid, {:ok, sum}) end defp _receiver(0, accum), do: accum defp _receiver(process_num, accum) do receive do {:ok, sum} -> _receiver(process_num-1, [sum] ++ accum) # 指定時間以上経過した場合にプロセスを停止して終了 after 1000 * ParallelSum.Config.waiting_limit_time_for_process() -> Logger.warn("[receiver] time over. so kill process") end end
起動時に生成するプロセス数と全ての結果の受信が完了した際にメインプロセスに結果を集約した結果を送信するためにメインプロセスのPIDを引数に持つ。再帰的に処理を行い、各プロセスから送信されてきた結果をアキュムレーターにて保持。カウンターの値が0になった時にメインのプロセスに最終的な結果を送信する。
集計を行うプロセスのための関数
./parallel_sum/lib/sum.ex
@doc """ コマンドメッセージを受信するまで算出処理を行わないwrap関数 チャンクはプロセス起動時に引数で受け取る """ def waiting_sum(lst) when is_list(lst) do receive do {:recursive, pid} -> sum = recurcive_sum(lst) send(pid, {:ok, sum}) # プロセスが停止するとベンチが行えなくなるため再帰 waiting_sum(lst) {:enum, pid} -> sum = sum(lst) send(pid, {:ok, sum}) # プロセスが停止するとベンチが行えなくなるため再帰 waiting_sum(lst) # 指定時間以上経過した場合にプロセスを停止して終了 after 1000 * ParallelSum.Config.waiting_limit_time_for_process() -> Logger.warn("[waiting_sum] time over. so kill process") exit(:time_over) end end
チャンク分割したデータ(配列)を受け取り、立ち上げるタスクに当たる関数。message passingによってチャンクを受け取る方法も考えたし、後に実装するつもりではあるが、今回はプロセスの事前立ち上げに焦点を当てているため引数経由でプロセス立ち上げ時にチャンクを受け取る方法を採用した。再帰的な処理を行わせているのはかなり特殊な対応で、benchfellaが同じベンチマークを上限時間内に何度も実行するため、再帰的に処理が行われるようにしておかねば2度目のベンチマーク時には事前に立ち上げたプロセスが誰一人、存在していないという状態になってしまうからになる。
肝となる部分がこの関数で、事前に立ち上げたプロセスがそれぞれ、集計開始のメッセージを受け取るまで待機するように作成してある。{:recursive, pid}か{:enum, pid}というメッセージを受け取ることで初めて並行和の処理を開始する。
メインプロセスのための関数
./parallel_sum/bench/init_sum_bench.exs
# 共通処理を関数化 def bench_helper(process_info, type_atom) do {process_num, calc_processes} = process_info # 受信用のプロセスを起動 # receiver = spawn(ParallelSum.Sum, :receiver, [process_num, self()]) self_pid = self() receiver = spawn(fn -> ParallelSum.Sum.receiver(process_num, self_pid) end) # それぞれのプロセスに算出開始のメッセージを送信 Enum.each(calc_processes, fn pid -> send(pid, {type_atom, receiver}) end) # 算出値を受信して合計 receive do {:ok, sum} -> Enum.sum(sum) end end
立ち上げたプロセス情報(プロセス数, PIDを保持した配列)を受け取り、「算出値の受信用プロセス」を起動させて、「集計処理のために引数経由でチャンクを受け取り起動済みのプロセス」それぞれに対してPIDを指定して集計開始のmessageを送信する。そして、最終的に各プロセスから受け取った結果をまとめたmessageを受信用のプロセスから受け取り、メインプロセスにて値を合計して終了する。
モジュール変数で使用している関数はこちら。大したことはしていないのでコードのリンクを貼っておきます。
github.com
いざ測定
ベンチマークを行行う前に設定条件について説明しておく。配列の要素数が100万程度(10Nのrangeで実行)の場合にベンチマークが制限時間内に終了しない問題にぶち当たり、これはコンピューターのスペック的に厳しいと判断。今回のベンチマークの配列の要素数の最大数は10万とし、1プロセスあたりが扱うチャンクの要素数は100としたので、並行和を実行するプロセスは最大で1万個生成されたということになる。普通にめっちゃ多くね。
実行したベンチマークはこちら
github.com
設定条件の一覧
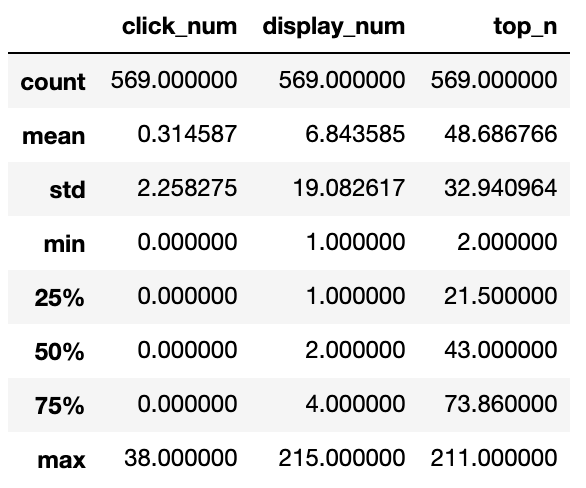
| 項目 | 設定値 |
|---|---|
| 最大配列要素数 | 100,000 |
| 生成する要素値の最大数(int) | 1,000 |
| 1プロセスあたりの最大要素数 | 100 |
| 最大生成プロセス数 | 10,000 |
| タスク実行最長許容時間 | 20seconds |
結果
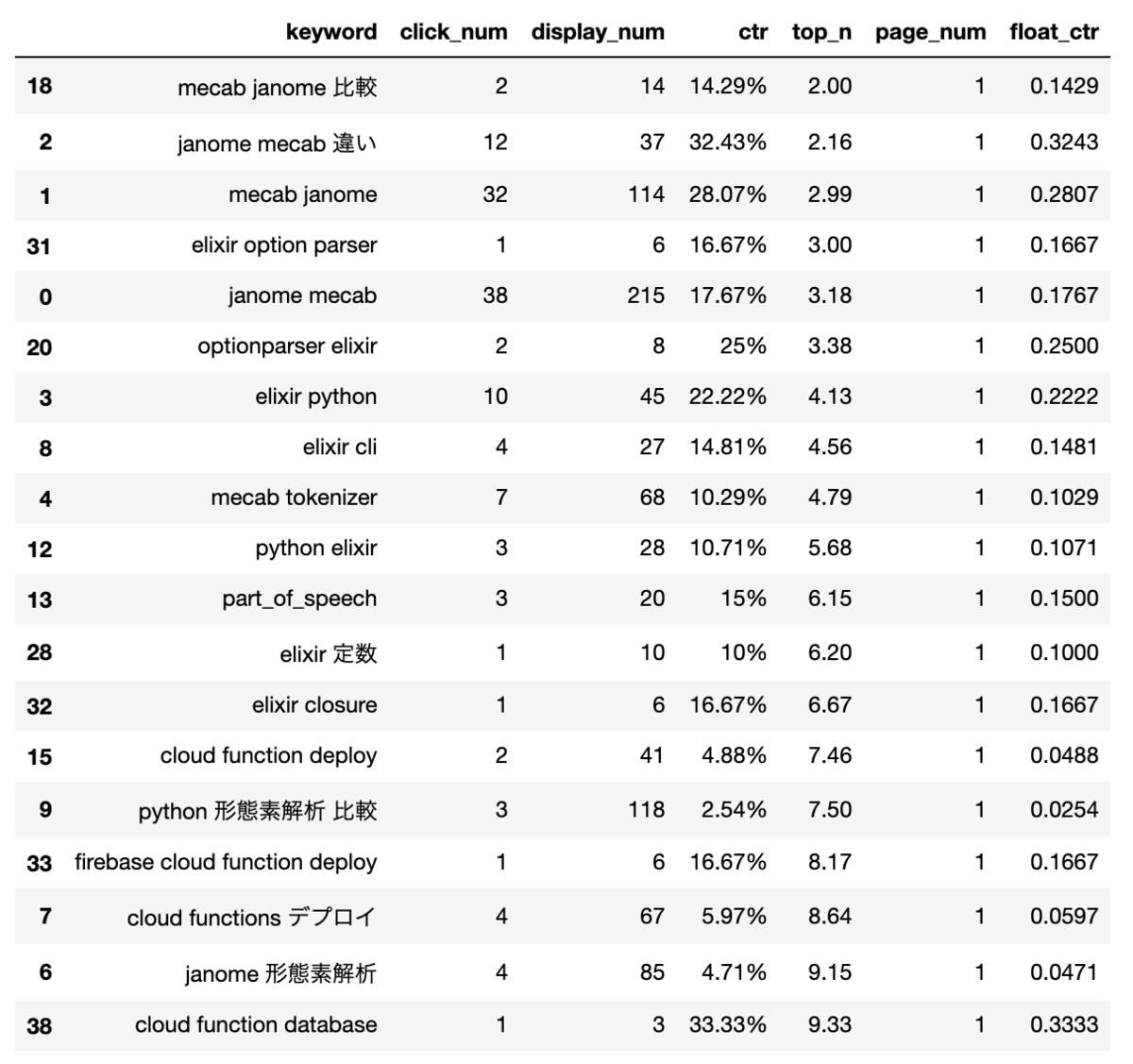
再帰関数を使用して並行和を算出した結果

Enum.sum()を使用して並行和を算出した結果

前回の結果(プロセスを事前立ち上げしないケース)


.snapshot
ParallelSum.InitBench parallel: enum 100 500000 2555564 ParallelSum.InitBench parallel: enum 1000 100000 2902751 ParallelSum.InitBench parallel: enum 10000 10000 1819477 ParallelSum.InitBench parallel: enum 100000 1000 1781611 ParallelSum.InitBench parallel: recursive 100 500000 2517027 ParallelSum.InitBench parallel: recursive 1000 100000 2878593 ParallelSum.InitBench parallel: recursive 10000 10000 1834528 ParallelSum.InitBench parallel: recursive 100000 1000 1710872
数値での比較
前回
| 算出方法 | データ数 | 1回あたりの実行時間(µs/op) |
|---|---|---|
| enum | 100 | 33.83112 |
| enum | 1000 | 349.8089 |
| enum | 10000 | 17106.37 |
| enum | 100000 | 4650929 |
| recursive | 100 | 22.67772 |
| recursive | 1000 | 243.1725 |
| recursive | 10000 | 10893.83 |
| recursive | 100000 | 1575123 |
今回
| 算出方法 | データ数 | 1回あたりの実行時間(µs/op) |
|---|---|---|
| enum | 100 | 5.111128 |
| enum | 1000 | 29.02751 |
| enum | 10000 | 181.9477 |
| enum | 100000 | 1781.611 |
| recursive | 100 | 5.034054 |
| recursive | 1000 | 28.78593 |
| recursive | 10000 | 183.4528 |
| recursive | 100000 | 1710.872 |
要素数が10万の時での比較
| 算出方法 | 前回 | 今回 | 何倍速くなったか |
|---|---|---|---|
| enum | 4650929 | 1781.61 | 約2610倍 |
| recursive | 1575123 | 1710.872 | 約920倍 |
考察と感想
確かにアドバイス頂いた通りにElixirではプロセスの起動部分が、並行化におけるかなりのオーバーヘッドになっているのはこの結果からも明らか。それにしても驚いた。こんなに速くなるものとは...。あと気になるのはチャンク分割がどれだけのオーバーヘッドになり得るかということで、事前にプロセスだけを立ち上げておいて、message passingにてチャンクデータを受け取る方式でのベンチマークも非常に気になる。
本来ならば別言語実装の同内容のベンチマークと結果を比較するべきだろうが、並行処理を初めて1年にも満たない人間が、気軽にプロセスを立ち上げて、気軽に並行処理を行えるElixirのストレスフリーなデザインは凄い。
またElixirで並行処理のパフォーマンスを活かすためには下記のような場合に適しているのではないか。
- 実行時前にプロセスを立ち上げられる設計がされている -> eg: サーバー起動時にプロセスを立ち上げ
- 事前にプロセスを立ち上げるべき目的になっている -> eg: 常駐プロセス
Elixir(Erlang)の採用事例を数多く見てきたが、GateWayであったり、stream serverであったり、プッシュ通知であったり...と、今回得られた知見とフィットしている。
次はmessage passingによってチャンクデータを受け取る方法でのベンチマークの測定を目指すこととする。
おまけ: なぜTaskが使えなかったのか
まず以下のログからTaskがasync()で起動された後に、await()で結果を取得するまでの間に待機状態となるのではなく、適宜処理を実行していることが分かる。
iex(1)> Task.async(fn -> IO.puts("nice boat") end) nice boat %Task{ owner: #PID<0.104.0>, pid: #PID<0.106.0>, ref: #Reference<0.3871736042.2998665217.74532> }
これは特に問題ないのだが、致命的な問題が2つある。
Task.await()が実行出来るプロセスの縛り
以下の検証用モジュールを用意してmain_validaterを実行するとerrorになる。どうやら公式ドキュメントにもある通り、Task.await()はTask.async()を用いてTaskを生成したPIDを持つプロセス内部でしか実行出来ない様だ。プロセスがリンクされているのだろうか。
When invoked, a new process will be created, linked and monitored by the caller. Once the task action finishes, a message will be sent to the caller with the result.
defmodule ParallelSum.TaskConf do @moduledoc """ Taskモジュールを使用して生成されたプロセスは生成したプロセスによってしか回収できないかを確認 """ @doc """ Taskを生成してmessage passing形式で返す """ def create_task(pid) do :timer.sleep(1000) task_info = Task.async(fn -> :ok end) send(pid, {:ok, task_info}) end @doc """ 自身のpidを用いてTask.awaitが問題なく実行可能かどうか """ def main_validater() do pid = self() spawn(fn -> create_task(pid) end) receive do {:ok, task_info} -> Task.await(task_info) end end end
実行結果
iex(1)> ParallelSum.TaskConf.main_validater ** (ArgumentError) task %Task{owner: #PID<0.203.0>, pid: #PID<0.204.0>, ref: #Reference<0.1202030419.853016577.25359>} must be queried from the owner but was queried from #PID<0.201.0> (elixir) lib/task.ex:594: Task.await/2
つまりは、「俺を生成したownerじゃないと結果が受け取れないで?」ということ。ベンチマークの際に実行するプロセスはモジュール変数をセットするプロセスと異なるプロセスであり、結果の受け取りが不可能なのではないかということに気づいた。
モジュール変数に任意の構造体は格納不可能
Taskは構造体であり、以下の様なデータになる。
%Task{ owner: #PID<0.164.0>, pid: #PID<0.169.0>, ref: #Reference<0.1718095132.2719481858.113828> }
先ほどのownerもTask構造体の内部に記録されているが、Task.async()の戻り値はTask構造体であるため、モジュール変数に格納することが出来ない。モジュール変数に格納可能なデータ構造は以下のみ。
- lists
- tuples
- maps
- atoms
- numbers
- bitstrings
- PIDs and remote functions in the format &Mod.fun/arity
「PID」ならいいんや。ということでspawn()によるプロセス生成とmessage passingの方針を採用したというわけになる。