この記事を書いた理由
GoogleアナリティクスやGoogleサーチコンソールといった優秀なツールがあり、使い方を解説する記事が多数ある一方で
- どう使えばPV数が増えるのか
- 収益を生み出すには何に注目するのか
といったテーマの記事が非常に少ないことに気づいた。現状(2020/02/16時点)で1日の平均PV数が「10」のこのブログがGoogleアナリティクスやGoogleサーチコンソールのデータを使用したデータ分析によってPV数が増えていくのかを記録することが一番の目的になる。
ブログの現状
プログラミング関連(特にElixirという言語)の記事をメインに興味のあることをブログを書いている。2019年の3月にブログを開始して、はや1周年を迎えようとしており、書いた記事数は2020/02/16日時点で「89件」。99%が3ヶ月以内にブログを挫折するらしいのでよく続いているなと自分でも思う。ほほとんど「アウトプットしたい」という気持ちだけで続いている。
:
:
と思っていたが、自分のブログのPV数(ページビュー)を最近、気にするようになって落ち込んでいる。
(バァァァァアアアン)
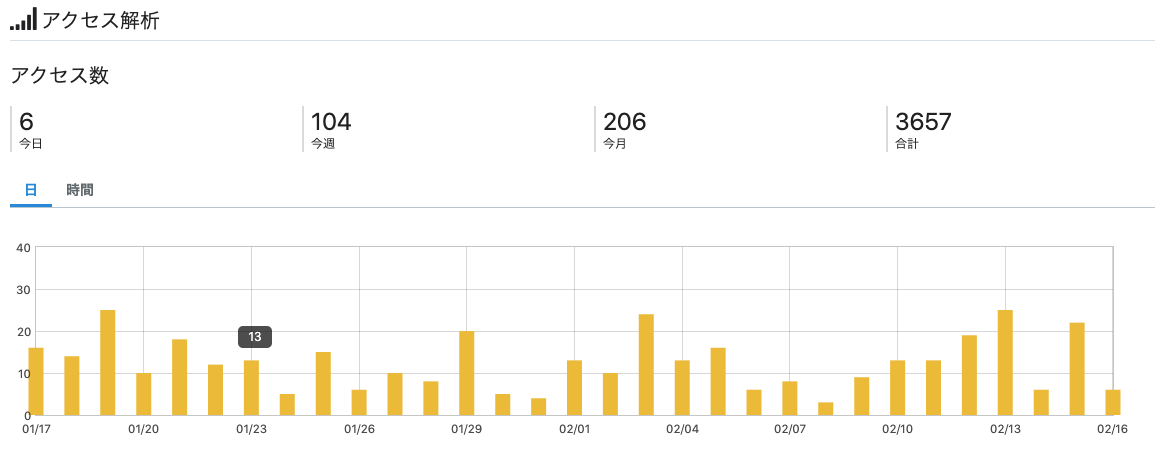
一年もやっててPV数の合計はだいたい3,600程度。1日のPV数は多くて30~40ぐらいで、低い時は5以下といった具合。つまり何が言いたいのかというと「書いた記事をほとんど見てもらえない」ということ。ショック...
この企画について
普通に不労所得ほしいです
どんだけ良い記事を書いていたと思っていても、見てもらえなければ自己満足のメモ。それはそれで良いけど、PV数が少ないということは収益の可能性も低いということ。2020年の抱負は「何かしらでマネタイズする」であり、不労所得を生み出したい。何故、不労所得が欲しいかというと3つの理由がある。
- 心の余裕を保つため
- 時間労働の限界性を感じたから
- 母親に楽をさせてあげたい
せっかくブログをやっていて独自ドメインも取ってるし、はてなもproで契約してるのなら最低限、ブログの維持費分だけでも収益を出したいところ。
収益を生み出すためには
じゃあ、どうやったら収益って増えるのかを考えると最もシンプルな答えは「PV数を増やすこと」になる。アドセンスなりアフェリエイトなりまずは見てもらえる機会を増やすこと。じゃあ、どうやってPV数って増やせるのかを考えると、答えはめちゃくちゃ複雑で明確な解はない。
とはいえ、ブログで収益を生み出している先駆者の方々は存在しており、実際に結果を出している。こういう時は先駆者の考えや施策を調べまくる。どうやら、彼らが言うには収益を増やすために「キーワードの分析」が非常に重要らしい。
- どんなキーワードがPV数を稼いでいるのか
- google検索結果の1ページ目を獲得出来ている記事はどれだけあるか
など...
しかしながら、この辺りのノウハウは有料であったり(買えよと言わないで)、絶妙に内部化されており、何となくでしか情報を手に入れることが出来ない。マネをするのも戦略としては当然考えたが、自分のブログのスタイルを変えることはしたくないのでマネできる所だけマネはする。そんなことを考えていてあることに気づいた。
「業務でデータ分析やってるし、勉強ついでに分析もやってマネタイズ出来たら最高じゃね?」
今回の分析で知見を貯めれば、ついでにデータ分析の知見も貯まるし、業務にも還元される上に、お金も貰えるかもしれないと考えるとやらない理由がない ということでこの企画をスタートしてみた。
実践編
分析に使用している全体のコードについてはgithubを参照下さい
github.com
対象のデータについて
自分のドメインを登録済みのGoogleサーチコンソール(通称:サチコ)から検索パフォーマンスのデータを.csv形式でダウンロード。
downloadのディレクトリに.csv形式のファイルが生成されているので、さっそく開いてみるが文字化け。
しかもMicrosoft Officeのライセンス切れてて、Excelも使えない。まぁ、元々Excelでやるつもりはなかったので、データ分析のマストアイテムjupyter notebook(いつもの)を立ち上げてダウンロードしたcsvを読み込むことに。
都合が良いので先にカラムの説明を少々。何故かというと日本語表記だと参照する際に面倒なので、英語表記にしているからで「自分のcsvにはそんなカラムはないんですけど」という誤解を生み出さないため。
(左: 元のカラム名, 右: 変換後のカラム名)
- 検索キーワード -> keyword
- クリック数 -> click_num
- 表示回数 -> display_num
- CTR -> ctr(検索結果として表示された時にどれだけクリックされているかの割合)
- 掲載順位 -> top_n
pandasのpd.read_csv()という関数を使って読み込んだ結果(jupyter notebookの1セルで見えるところだけ)
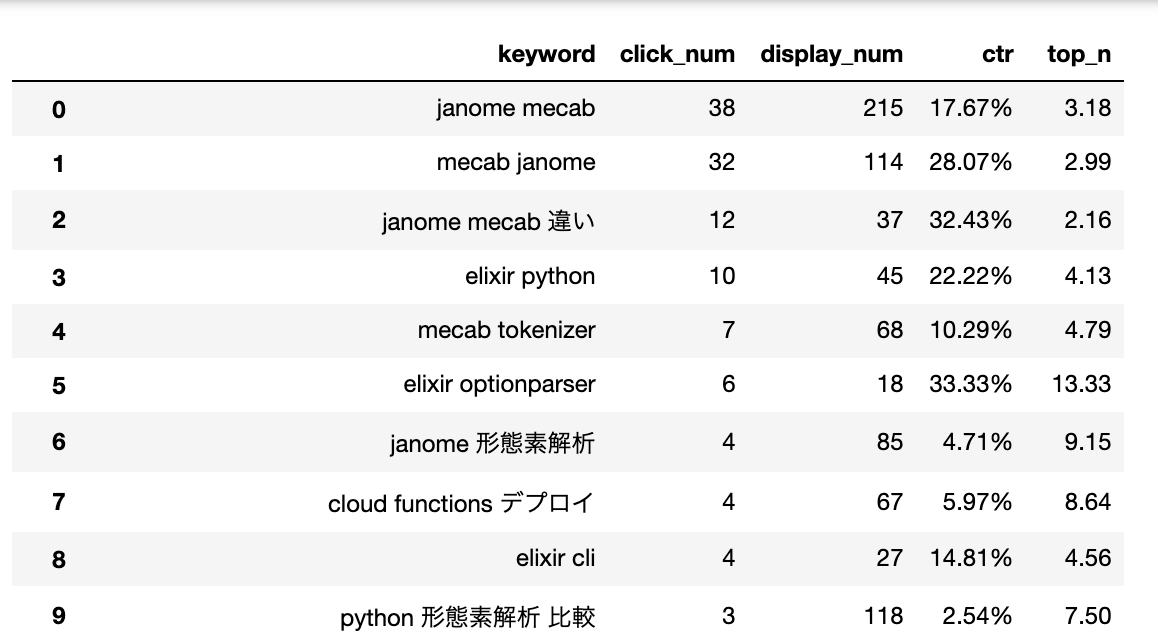
すでに色々と思うことがあるが、感想としては色んなキーワードで調べられているなぁという程度...。ここから何をすれば良いのやら。順に考えていこう。
データの概要を見てみよう
何から始めて良いのか恐ろしいほど、全く分からないので、まずは定番データの概要を見てみる。pandasのdescribe()を使って表示したものがこちら
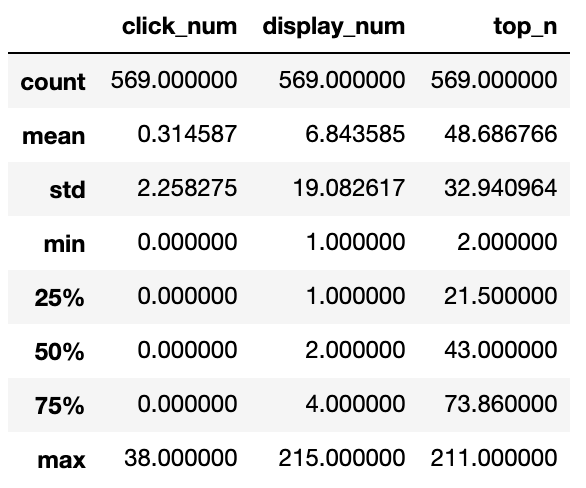
これだけでも色々なことが分かる。気になったことをリスト出ししてみた。
- mean: top_nより -> 掲載順位は大体が4ページ目ぐらい -> 1ページ以降を閲覧する割合はかなり低かったのでこれは致命的
- min: top_nより -> 検索すれば上から2番目(1ページ目)に表示される記事があることに驚きを隠せない
- 50%: top_nより -> 50%の時点で掲載順位の値が43(すなわち4ページ目)であるため、半数以上の記事は検索からの流入を全く期待出来ない
- 25%: top_nより -> 25%の記事は悪くても2ページ以内に表示されている様で20記事ぐらいは良い位置を取っている
- 全体的: click_numより -> めちゃくちゃ低い
- 全体的: display_numより -> この値から何を感じて良いのか分からない
ネガティブな所に目が行きがちだが、上から2番目に表示されている記事があったり、1ページ目に登場する記事が割とあったりとで素直に驚いた。PV数を稼ぐ上で「どれだけ上位の検索順位をキープできるか」かが重要だと判断出来るので、どのようなキーワードの組み合わせで1ページ目を抑えているのかを次に見ていこう。
1ページを取っているキーワード
その前にtop_nの数値では何ページ目に表示されるのかが直感的に分からないので何ページ目に表示されるかを示すpage_numというカラムを追加して、page_numの値が1になるキーワードだけを抽出した。合わせてctrの値が0以外のデータ(少なくとも1回はクリックされている)と0のデータに分けてみた。
表示されるページが1ページかつ、クリックされたことがあるキーワードの組み合わせ
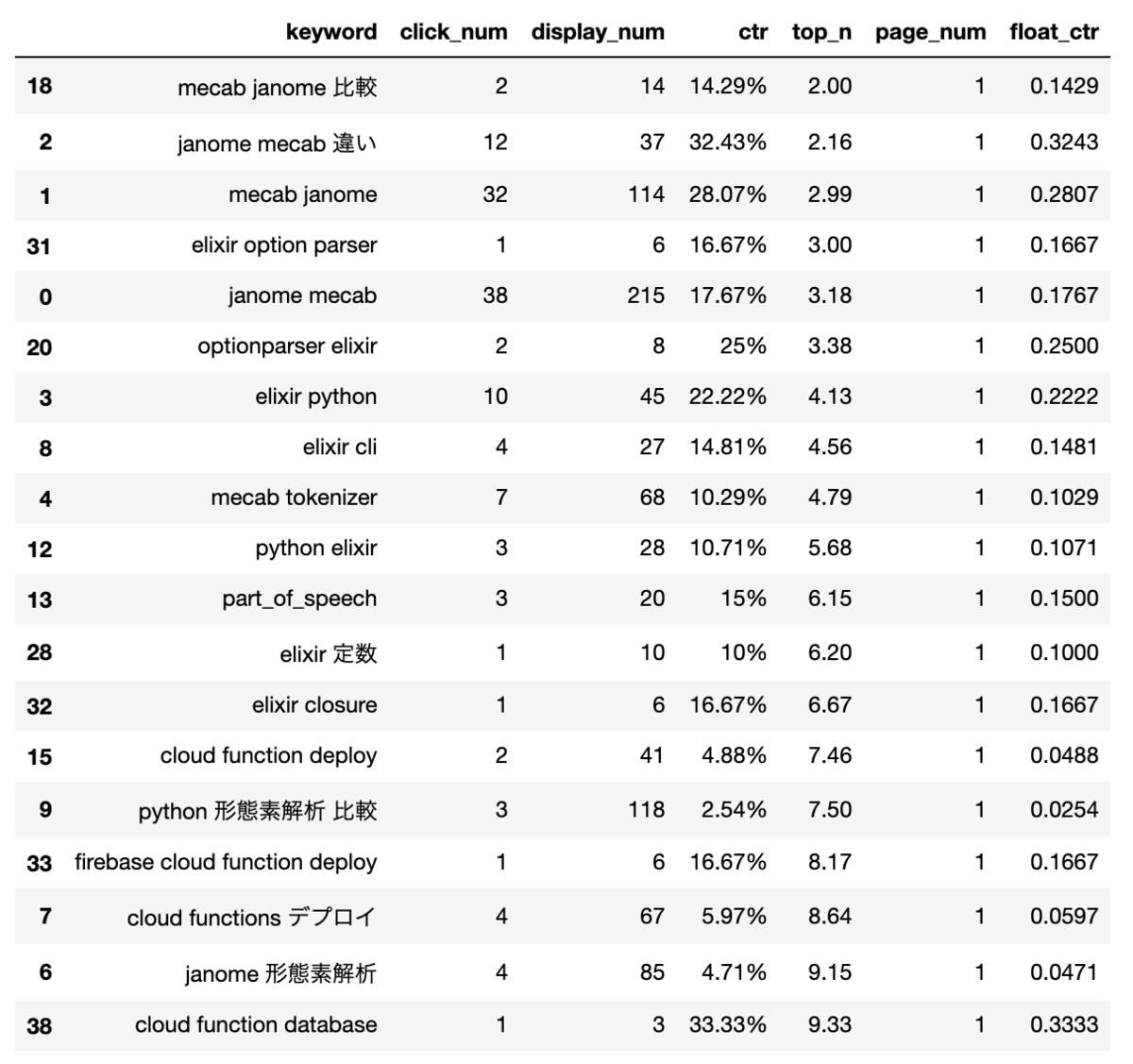
見たまんまの考察
mecabとjanome(形態素解析器)の組み合わせ、もしくは「janome+ 何か」が強い ->janomeの記事は2件だけなのになんじゃこれ- メインでやってる
Elixir(プログラミング言語)に関係するキーワードがちらほら見つかる - 地味に
cloud functionが強くて高いctr値を保持している ->cloud fuctionの記事も2つのみだが
表示されるページが1ページかつ、クリックされたことががないキーワードの組み合わせ
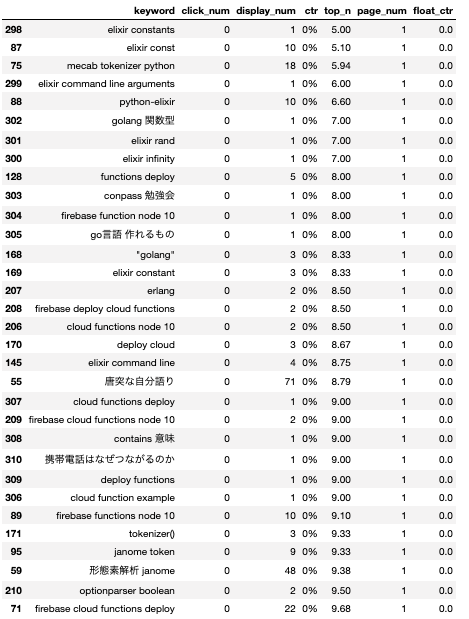
見たまんまの考察
- やはり1ページに登場しているのは「
janome,Elixir(elixir),cloud function」に関係するキーワードの組み合わせ elixir const多すぎ。1ページを取ってるのでctrあげたい- connpass 勉強会で1ページ取ってるのやばい。ctrあげたい
Elixirに関連する入門記事や、基礎知識に関するキーワードが皆無。これはつらい(ほとんどがElixirに関する初級~中級の記事なため)
比較としてpage_numが4以上のキーワードの組み合わせも抽出した。数が多すぎるので部分的に。
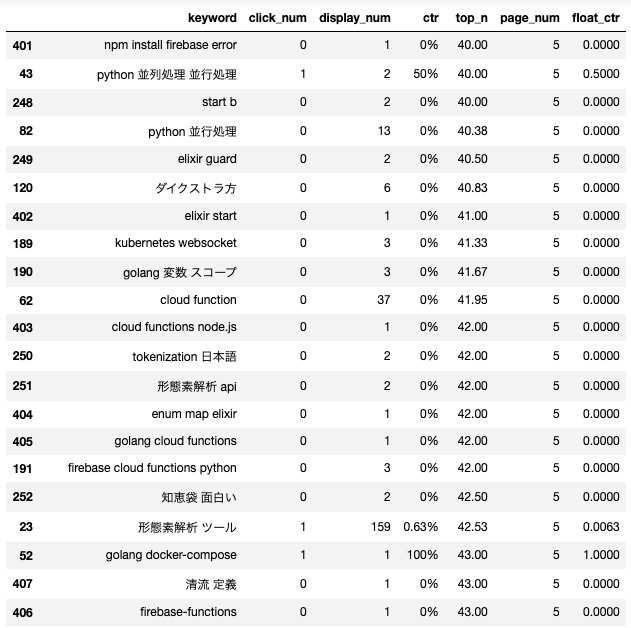
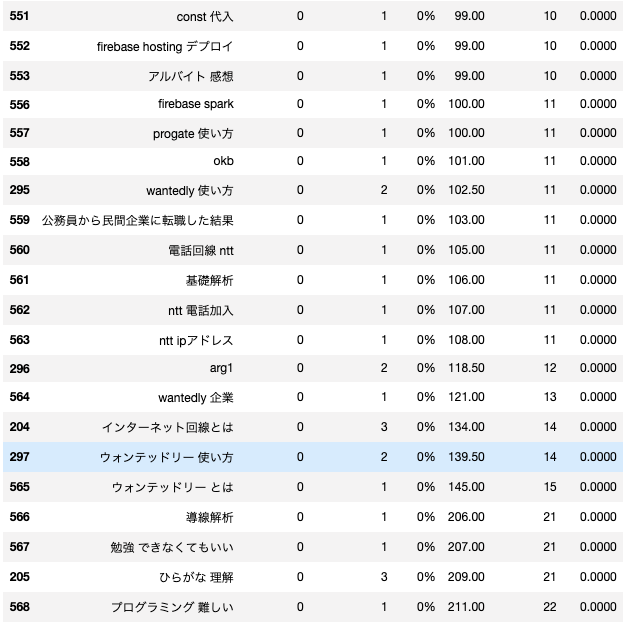
見たまんまの考察
- 訳の分からない単語が多い
- ビッグネームの単語が多くて、なぜかヒットしてしまいページが大きな数値に
- とはいいつつも、個人的には落としたくない単語もある(elixir enum mapとか、おそらく海外からの検索だろうけど)
一応page_num=2(2ページ目に表示)に該当するデータも最後に確認。個人的にElixir(elixir)とセットで調べられている単語を知りたいのでElixirを含むキーワードのみを抽出。
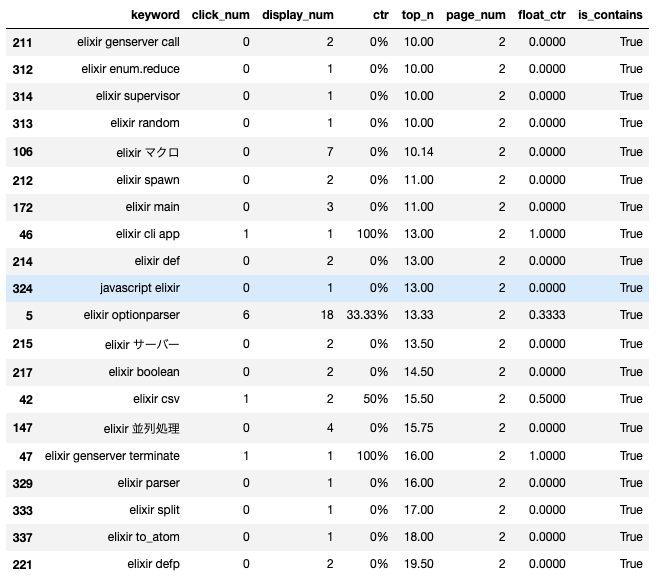
見たまんまの考察
- elixir 並行処理が2ページ目って凄い。ただクリックされていないので残念
- 他のプログラミング言語 +
Elixir(elixir)という組み合わせが多い。「python使いの人のためのElixirの始め方」みたいな記事書くと良さそう - コアな単語が少なく
Elixir(elixir)+syntaxが多い。 - 特に狙っていたキーワードの組み合わせがなくて消化不良感
頻出キーワードからの考察
自分のブログを第3者から見た時(検索した時)にどのようなジャンルを扱っているブログなのかを考察するために、現時点で検索に使用されているキーワードをスペース区切りでsplitしたものをカウントしてみた。結果は降順ソート済みで数多いので、上位20件と下位10件をお見せします。
[No.1]: elixir: 86 [No.2]: python: 74 [No.3]: firebase: 66 [No.4]: functions: 47 [No.5]: cloud: 46 [No.6]: golang: 33 [No.7]: mecab: 31 [No.8]: janome: 22 [No.9]: 形態素解析: 22 [No.10]: deploy: 20 [No.11]: function: 18 [No.12]: authentication: 13 [No.13]: websocket: 13 [No.14]: node: 11 [No.15]: ntt: 11 [No.16]: バイト: 9 [No.17]: login: 8 [No.18]: 並行処理: 8 [No.19]: tokenizer: 7 [No.20]: request: 7 : [No.442]: okb: 1 [No.443]: 公務員から民間企業に転職した結果: 1 [No.444]: 電話回線: 1 [No.445]: 基礎解析: 1 [No.446]: 電話加入: 1 [No.447]: ipアドレス: 1 [No.448]: 企業: 1 [No.449]: 導線解析: 1 [No.450]: できなくてもいい: 1 [No.451]: 難しい: 1
(誰がokbで調べたんだ...)
見たまんまの考察
今までの考察通り、現在、自分のブログは以下のジャンルに支えられていることが分かる。
Elixir(elixir)pythonjanomemecab(形態素解析)cloud function
Elixir(elixir)が1位になっているのは嬉しいのだけど、このブログにかけている労力はElixir(elixir) > python > janome / mecab, cloud functionの順に大きいが、数字ではほとんど差がないので元々、単語が持っているトレンド性、つまりは人気度が全然違うんだろうなと思う。そこでGoogle Trendsを使って、人気度を比較してみた。ここで出ている数値は「人気度」ということでどのように算出されているかはよく分からない。
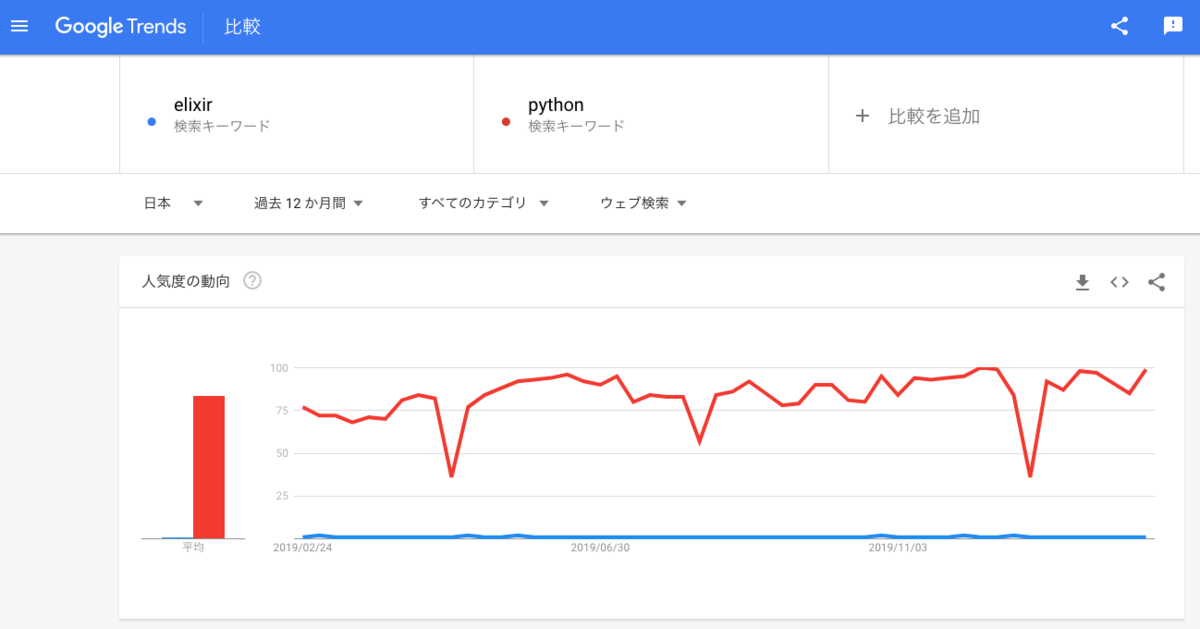 https://trends.google.co.jp/trends/explore?geo=JP&q=elixir,python
https://trends.google.co.jp/trends/explore?geo=JP&q=elixir,python
pythonが平均で84という人気度を維持する中、Elixir(elixir)は平均も1、いつでも1...。これは確かに単語のパワーが違いすぎると認めざるを得ない。
これからすべきこと
分析から分かったこと
- 多くの記事の掲載順位は4ページ目ぐらい で、これは致命的
- 25%の記事は悪くても2ページ以内に表示されている様で20記事ぐらいは良い位置を取っている
- 現状のブログを支えているキーワードは「
elixir,python,janome mecab,cloud function」でほとんどのPVはこの4つの関連するキーワードの組み合わせで獲得されている - 間違いなくキーワードにはパワーの優劣がある。
elixirをメインで扱いたいがptyhonには遠く及ばない
反省すべきこと
キーワードの選定を全く意識していなかった。書きたいものを書くだけではPVが稼げないのは数字から分かる。残念ながらElixir(elixir)というトピックだけではPVを稼ぐことは難しいため、何かしらの戦略が必要になってくるが脳筋で「Elixir(elixir)かつコアな記事」を書き続けていたことを反省。それもそれでブログとしてはありだけど、それだけではなく、流入を行うための記事も必要になる。
掲げた戦略
Elixir(elixir)という単語だけではパワーに欠けるため、検索キーワードにも見られた「他プログラミング言語 xElixir(elixir)」という分野を狙っていく(eg: python好きのためのElixir(elixir)入門みたいな)- PVを稼いでいると思われる記事が何となく分かったので検索されているキーワードの組み合わせの形に合うようにリライトを行う
- パワーのある単語で1ページ目を狙う(eg: 「プログラミング 独学」, 「プログラミング 挫折」など)
次回について
今回の分析で分かったことと、掲げた戦略に対する取り組みを行い、どれだけPV数が変化するのかを次回の記事にて報告しようと思います。自分自身、今まで学んだ分析に合わせて、トライアンドエラーで得られる知見が凄い楽しみかつ、PV数が増えるかもしれないという明確な報酬があるため気合いが入りまくっています。
では、第1回の結果をお楽しみに。



