トピック
今回で第10回目の勉強会を開催致しました
elixir-sr.connpass.com
3月の下旬に始めた当勉強会も、気づけば10回もやってたのかと感慨深い
「どうやって運営してるんですか?」とよく聞かれることがあるが別に何か特別なことはしていないはず
ただ、自分の知りたいことをテーマとして会場に持ち込んだり(ある程度アジェンダは組む)
参加者の方から気になってることを聞いて、調査しながら手を動かしたりと
ポイントは毎回のテーマの濃さよりも、とりあえずは続けることだと考えている
続けている内に内容も濃くなっていくはず
今回は前々から気になっていた
パターンマッチによる条件分岐とif, caseのような制御構文とどっちが速いのかを測定してみた
Elixirのお作法としてはパターンマッチを推奨しているが、実際は速度はどうなんやろと単純な疑問にて開催
清流elixir-infomation
開催場所: 丸の内(愛知)
参加人数: 5 -> 5
コミュニティ参加人数 : 13 -> 13
20190810現在
第10回の勉強会の内容について
Elixirに用意されている制御構文について
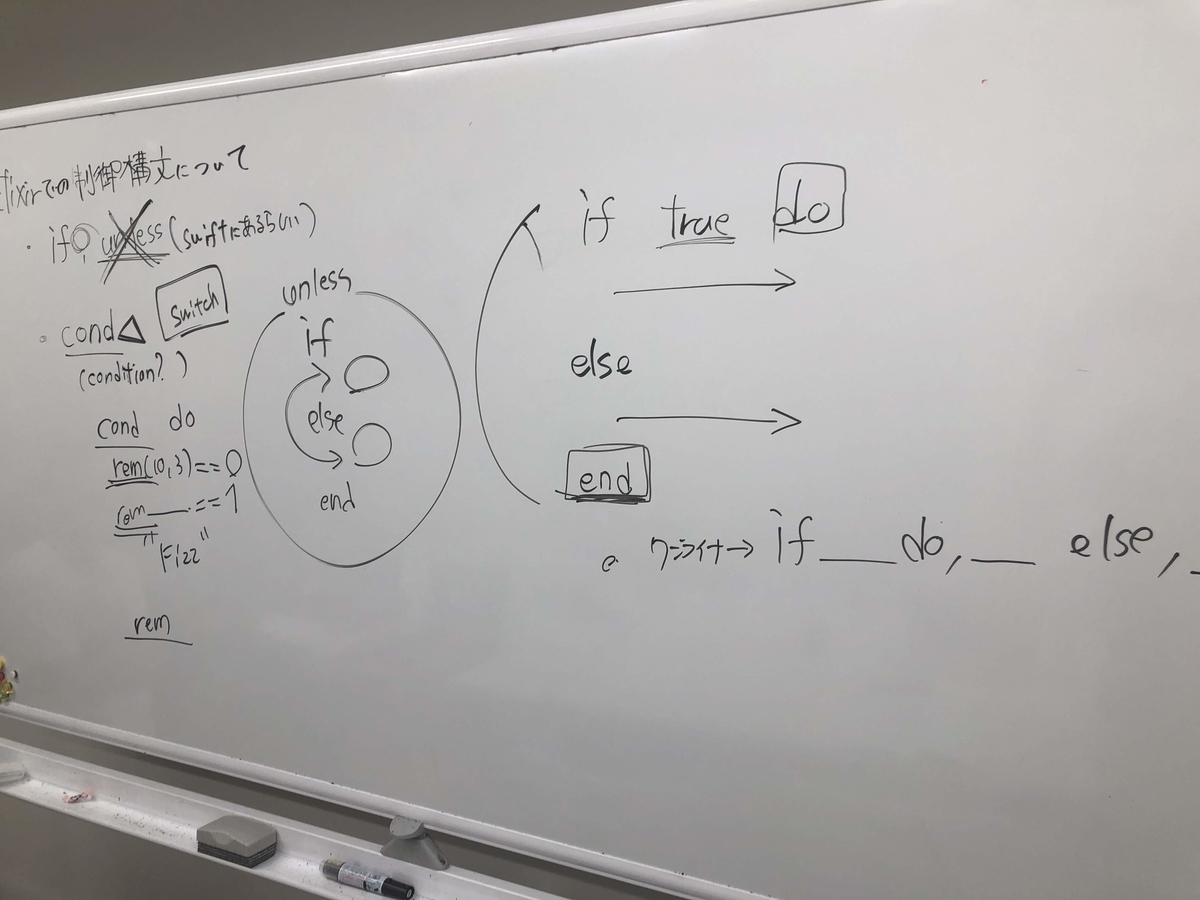
パターンマッチによる条件分岐を推奨しているもののElixirにも制御構文は用意されている
それぞれについて詳しい説明はしないが、ざっくりと列挙する
- if else(else if は無い)
- unless
- case
- cond
ifやcase(jsでいうswtichに近しい)については説明するまでもないので省略
unlessとcondについては私は普段全くと言っていいぐらい使っていないので、今回初めて触れることになった
unlessについて
プログラミングElixirではunlessについては色々と酷い扱いがされている
実際のユースケースが私にも想定できない。not使えばええやんって
どうやらrubyではnotを使うことを推奨していないようでunlessを使う機会があるらしい
どっちにしろ極力使わないようにしようと思っている
unless true do IO.puts("--> True") else IO.puts("--> False") end # result --> True
condについて
condはconditionの略なんやろうな〜と思ってる。caseに似ているが条件式を複数個記述することが可能
以前、入門会で書いたFizzBazzもcondを使うとこんな感じにまとめる
num = 15 cond do rem(num, 15) == 0 -> IO.puts("FizzBuzz") rem(num, 3) == 0 -> IO.puts("Fizz") rem(num, 5) == 0 -> IO.puts("Bazz") true -> IO.puts("another") end # result FizzBuzz
場合によっては使い所がありそうな気がするが、パターンマッチで条件分けが可能なので個人的な使用率はかなり低い
Elixirの制御構文について3段階で総合評価(max=3)をそれぞれにすると(個人的主観)
| 制御構文 | かきやすさ | 使用頻度 |
|---|---|---|
| if | 3 | 3 |
| case | 2 | 2 |
| unless | 3 | 1 |
| cond | 2 | 1 |
Elixirでの速度測定について

速度の測定についてはElixirでの実行速度の測定と色々と実験してみた【Enun.sum vs Enum.reduce etc...】にまとめたのでこちらを参照してほしい
ざっくりとだけまとめておくと、Elixirには速度測定のための関数が用意されていないためErlangの:timer.tcという関数を使用する
:timer.tcには3種類の引数パターンがある
- :timer.tc(function)
- :timer.tc(function, [arguments])
- :timer.tc(module, :function, [arguments])
戻り値は2つの要素をもつタプルになっている
{sec, result} = :timer.tc(function)
速度を測定してみる
ここまで準備が整ったところで、さっそく今回の目標である
「パターンマッチと制御構文どっちがはやいねん」を検証する
比較するモジュールは以下。めっちゃシンプルな受け取った果実名に対応する値段を返すのみ
リストを受けて測定をするためにhelper関数(helper_for_price)をそれぞれに用意している
# pattern match defmodule Sample do def helper_for_price(lst) do Enum.map(lst, fn f -> price(f) end) end def price("apple") do 110 end def price("banana") do 70 end def price("orange") do 120 end end # 制御構文(case) defmodule Sample2 do def helper_for_price(lst) do Enum.map(lst, fn f -> price(f) end) end def price(fruit) do case fruit do "apple" -> 110 "banana" -> 70 "orange" -> 120 end end end
とりあえず記念(何の)に1度、それぞれを測定してみる
{sec1, _res} = :timer.tc(Sample, :price, ["apple"])
{sec2, _res} = :timer.tc(Sample2, :price, ["apple"])
IO.puts("pattern match: #{sec1}")
IO.puts("case: #{sec2}")
# result ----
# pattern match: 1
# case: 0
早すぎてcaseが0になってて草
単位はマイクロ秒なので恐ろしく速い
次に100個の要素を持つリストをhelper関数に渡して測定してみる
そのためにランダムでfruit名("apple" or "orange" or "banana")を指定個数分、要素にもつリストを用意する必要があるため
Enumを使ってさくっと作成
lst_size = 10 fruits = ["apple", "banana", "orange"] fruits_lst = Enum.map(1..lst_size, fn _ -> Enum.random(fruits) end) IO.inspect(fruits_lst) # result # ["orange", "apple", "banana", "banana", "orange", "apple", "banana", "orange", "apple", "apple"]
それぞれのモジュールのhelper関数に作成したリストを渡して速度を測定する
リストの要素数は適当に100000にした
lst_size = 100000 fruits = ["apple", "banana", "orange"] fruits_lst = Enum.map(1..lst_size, fn _ -> Enum.random(fruits) end) {sec1, _res} = :timer.tc(Sample, :helper_for_price, [fruits_lst]) {sec2, _res} = :timer.tc(Sample2, :helper_for_price, [fruits_lst]) IO.puts("pattern match: #{sec1}") IO.puts("case: #{sec2}") # result # pattern match: 13832 # case: 9151
先ほどはほとんど差がなかった要素数が増えると如実に結果に現れた
ほう、何と制御構文の方が速いではないか
同じ条件で測定を100回行い平均値を算出してみる
lst_size = 100000 fruits = ["apple", "banana", "orange"] fruits_lst = Enum.map(1..lst_size, fn _ -> Enum.random(fruits) end) try_num = 100 sec1s = Enum.map(1..try_num, fn _ -> :timer.tc(Sample, :helper_for_price, [fruits_lst]) end) |> Enum.map(fn {sec, _} -> sec end) |> Enum.sum() sec2s = Enum.map(1..try_num, fn _ -> :timer.tc(Sample2, :helper_for_price, [fruits_lst]) end) |> Enum.map(fn {sec, _} -> sec end) |> Enum.sum() IO.puts("pattern match: average -> #{sec1s / try_num}") IO.puts("case: average -> #{sec2s / try_num}") # result # pattern match: average -> 22682.64 # case: average -> 20379.93
やはり若干だが、caseの方が速いよう
ただほぼ誤差程度だと言えるので、だからパターンマッチよりも制御構文使った方が良いかというとそうではないと考える
公式がパターンマッチによる分岐を推奨しているので脳死で私はそちらを選択する
ただ、こうして数値として出してみることで考える機会になったので非常によかった
次回について
まだ内容について特に決まっておらず、現在模索中
そろそろ並列処理をやってもいいかなとも思っているし、phoenixをやりたいとも思っている
興味のあることや、気になるテーマがあればコメント、twitterなどでご意見を頂ければと思います
バラエティみたく気になるテーマを調査しますので