Elixirにqueueがなかった件
しかし、Erlangには用意されていた
Erlangの公式ドキュメントにばっちしqueueについて記述されている
Elixirで解決できない時はErlangのドキュメントを見るというのは本当ですね
Elixirからのqueueの使い方
新規のqueue作成
2つのリストを持つタプルの形式で値が返ってくる
que = :queue.new() iex> que {[], []}
queueに新たなデータを追加
new_que = :queue.in("okb", que) iex> new_que {["okb"], []}
先頭に待ち構えているデータの確認
iex> :queue.get(new_que) "okb"
.getメゾットでは取得したデータが元のqueueに残っているままなので
取得したデータが削除されるようにするには以下のようにする
iex(12)> :queue.out(new_que) {{:value, "okb"}, {[], []}}
取得に成功するとタプルの第1要素に:valueというタプルと共に取得した値が返ってくる
第2要素には取得後のqueueが返ってくる(今取得した値は含まれていない)
こいつにパターンマッチさせるにはこんな感じでいける
{{:value, value}, rest} = res
iex> value
"okb"
iex> rest
{[], []}
基本的に使うのはこのあたりなんじゃないかと勝手に思ってます
以上を踏まえてElixirで幅優先探索を実装します
ゆるく分かる幅優先探索について
すでにもっと分かりやすく解説してくださっている記事などたくさんあるのでざっくりと
僕の友人にプログラマーがいるか知りたいとします
この場合にどのように調べていくべきでしょうか
まずは連絡の取れる友人に一通り聞いて回り、プログラマーがいるかどうか確認します
もしこの時点でプログラマーを発見できれば探索は終了です(試行回数:1)
しかし、友人からプログラマーを発見できなかった場合は次の試行に移ります
次の手は自分の友人の友人にプログラマーがいるかどうかを確認します
友達の友達ってやつですね
この時点でプログラマーを発見できれば探索は終了です(試行回数:2)
見つからなかった場合は友達の友達の友達をあたります
この試行を発見できるまで、もしくは試行回数が上限に達するまで行います(試行回数:n)
このようにまずは近い(友人)ところを全て調べて
次に遠い(友人の友人)ところを順次、調べていくというのが
幅優先探索だと思っています
幅優先探索にはグラフが必要不可欠
友人関係というネットワークをグラフを使って表現するとこのような図になる
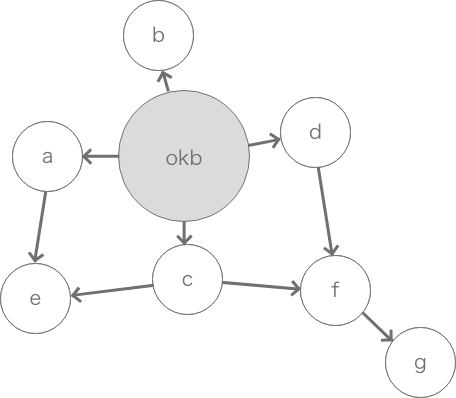
またグラフをデータで表現するとこんな感じの構造になる
friends = %{ okb: [:a, :b, :c, :d], a: [:e], b: [], #友人がいない(悲しいね) c: [:e, :f], d: [:f], e: [], f: [:g], g: [] }
Elixirで書いてみる
bfsというヘルパー関数を用いて中心のネットワーク位置を決定している
要は誰を中心として探索を行うかということを決めている
defmodule Algo do def bfs(graph, center, target) do #中心地点を決定し、queueを新規作成して追加 que = :queue.in(graph[center], :queue.new()) _bfs(graph, target, que) end defp _bfs(graph, target, que) do #queueから値を取り出して判定 case :queue.out(que) do {{:value, val}, rest} -> if target in val do #対象のデータが見つかれば終了 {:exist, target} else #取得したリストの要素を1つずつqueueに追加していく next_que = Enum.reduce(val, rest, fn key, que -> :queue.in(graph[key], que) end) _bfs(graph, target, next_que) end #queueが空になったら終了 {:empty, _} -> :not_found end end end
呼び出しはこんな感じになる
#グラフの用意(もっと面白いやつを作ればよかった) graph = %{ okb: [:a, :b, :c], b: [:d, :e], a: [:e], c: [:f, :g], d: [], e: [], f: [], g: [] } res = Algo.bfs(graph, :okb,:f) IO.inspect(res) #result: {:exist, :f}
いつものように簡易テストを行なってみる
tests = [ Algo.bfs(graph, :okb, :f) == {:exist, :f}, Algo.bfs(graph, :okb, :h) == {:not_found}, Algo.bfs(graph, :b, :f) == {:not_found}, Algo.bfs(graph, :c, :f) == {:exist, :f} ] IO.inspect(tests) #result: #[true, true, true, true]
いい感じですね
ただこのままだと無向グラフの場合に無限ループを引き起こす可能性があるので
一度queueに追加された値はqueueに追加しないように処理を追加します
既に追加された値はどうかはaccumを使って判定しています
defmodule Algo do def bfs(graph, center, target) do que = :queue.in(graph[center], :queue.new()) _bfs(graph, target, que, []) end defp _bfs(graph, target, que, accum) do case :queue.out(que) do {{:value, val}, rest} -> if target in val do {:exist, target} else #accumに存在していないデータのみ抽出 val = Enum.filter(val, fn x -> x not in accum end) next_accum = val ++ accum next_que = Enum.reduce(val, rest, fn key, que -> :queue.in(graph[key], que) end) _bfs(graph, target, next_que, next_accum) end {:empty, _} -> {:not_found} end end end
簡易テストを実行
tests = [ Algo.bfs(graph, :okb, :f) == {:exist, :f}, Algo.bfs(graph, :okb, :h) == {:not_found}, Algo.bfs(graph, :b, :f) == {:not_found}, Algo.bfs(graph, :c, :f) == {:exist, :f} ] IO.inspect(tests) #result: #[true, true, true, true]
queueの使い方を色々、試すのに時間がかかった
Elixirでのデータの動かし方についてはかなりマシになってきたとは思ってます(自己満
もっとこうした方が良いよなどありましたら教えてください